

Nota: SparkSession se ha convertido de hecho en un punto de entrada a Spark para trabajar con RDD, DataFrame y Dataset, desde Spark-2.0 (SparkContext era punto de entrada antes de salir SparkSession pero sigue usando) .
Que es SparkSession
-. SparkSession se esta convirtiendo en la puerta de entrada a PySpark para trabajar con RDD y DataFrame, “cómo crear SparkSession” y usar la spark variable-SparkSession predeterminada de pyspark-shell. Esta es la puerta de entrada a la funcionalidad de PySpark para crear mediante programación PySpark RDD, DataFrame. Su objeto spark está disponible por defecto en pyspark-shell y se puede crear mediante programación usando SparkSession.
-. pyspark.sql import SparkSession se an incluido una nueva clase SparkSession ( ) en la version Spark-2.0 SparkSession es una clase contiene para todos los diferentes contextos (SQLContext y HiveContext, etc.). Por la tanto se puede usar en sustitucion con los contextos: SQLContext, HiveContext y otros contextos definidos antes de version Spark-2.0.
. SparkSession sería la primera entrada para programar con RDD, DataFrame y Dataset. SparkSession se creará usando SparkSession.builder seria los patrones de construcción.
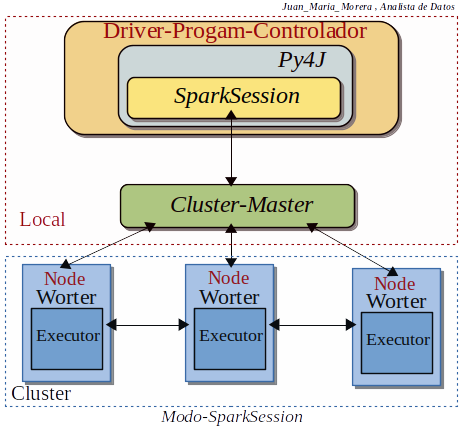
SparkSession incluye todas las API:
- SparkContext,
- contexto SQL,
- StreamingContext,
- HiveContext.
-. SparkContext no a sido substituido por completo por SparkSession, muchas funciones de SparkContext todavía están disponibles. SparkSession crea internamente SparkConfig y SparkContext con la configuración proporcionada con SparkSession.
-. No tenemos limites de crear tantos SparkSession como necesitemos en una aplicación PySpark utilizando SparkSession.builder() o SparkSession.newSession(). En una sesión de Spark cuando desea mantener las tablas de PySpark (separadas lógicamente) se necisitan muchos objetos.
- Comandos para trabajar con SparkSession:
- createDataFrame() Esto crea un DataFrame a partir de una colección y un RDD.
- getActiveSession() Devuelve una sesión activa de Spark.
- udf() Crea un PySpark UDF para usarlo en DataFrame , Dataset y SQL
- read() Devuelve una instancia de DataFrameReaderclase, esto se usa para leer registros de csv , parquet , avro y más formatos de archivo en DataFrame.
- readStream() Devuelve una instancia de DataStreamReader clase, esto se usa para leer datos de transmisión.
- sparkContext() Devuelve un SparkContext
- sql() Devuelve un DataFrame después de ejecutar el SQL mencionado
- sqlContext() Devuelve SQLContext .
- stop() Detener el SparkContext actual .
- table() Devuelve un DataFrame de una tabla o vista.
- version() Devuelve la versión de Spark en la que se ejecuta su aplicación, probablemente la versión de Spark con la que está configurado su clúster.
Un ejemplo básico pero real:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName(«Python Spark SQL basic example«) \
.config(«spark.some.config.option«, «some-value«) \
.getOrCreate()
Recopilando:
SparkSession es un punto de entrada de PySpark, y crear una instancia de SparkSession sería la primera declaración que escribiría en el programa, se puede crear usando el método builder() .
Referencias: (Entorno–Moreluz)
Referencias: Para-saber-mas