

Nota: SparkContext esta presente a partir de la versión Spark-1, es el punto de entrada a Spark y PySpark, Crear SparkContext es lo primer que tenemos que hacer para usar RDD , Acumuladores y Variables de difusión en el clúster mediante programación, es el objeto sc es una variable predeterminada disponible en spark-shell y PySpark.
Que es SparkContext
-. SparkContext es la entrada a cualquier funcionalidad de Spark, al ejecutar cualquier aplicación Spark, se inicia un Programa-Controlador (Driver-Program), que tiene la función principal y SparkContext se inicia en el Programa-Controlador . El Programa-Controlador luego ejecuta las operaciones dentro de los Ejecutores en los Nodos-trabajadores (Nodo-Worker).
-. SparkContext necesita Py4J para lanzar JVM y crea un JavaSparkContext, de forma predeterminada, PySpark tiene SparkContext esta a nuestra disposición como ‘sc’ .No tenemos que crear un nuevo SparkContext por que ya lo tenemos, la creación de SparkContext fue el primer paso para programar con RDD y conectarse a Spark Cluster.
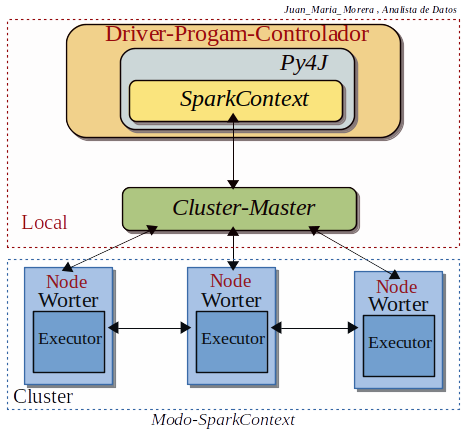
Nota: Con este diagrama podemos visualizar los diferentes conceptos , bloques y conseguir una mejor compresión de este post.
Nota: La API de Spark Python (PySpark) expone el modelo de programación de Spark en mi caso a Python y Jupyter, PySpark está creado con la API de Java de Spark, PySpark shell es el encargado de vincular la API de python al Núcleo-Spark e inicializar el Spark-context.
Nota: Cada aplicación Spark tiene un controlador (driver) que inicia las operaciones paralelas en un clúster. Este controlador (driver) contiene la función principal de nuestra aplicación y define conjuntos de datos distribuidos en el clúster, luego les aplica operaciones. Para ejecutar estas operaciones, los controladores (driver) generalmente administran una cantidad de nodos (los ejecutores) .
Nota: En PySpark estos son los parámetros que puede tomar un SparkContext.
URL del clúster al que se conecta:
- sc = pyspark.SparkContext (master=’None’)
Nombre de su trabajo:
- sc = pyspark.SparkContext (appName=’None’)
Directorio de instalación de Spark:
- sc = pyspark.SparkContext (sparkHome=’None’)
Archivos .zip o .py para enviar al clúster y agregar a PYTHONPATH:
- sc = pyspark.SparkContext (pyFiles=’None’)
Variables de entorno de los Nodos-Worker:
- sc = pyspark.SparkContext (environment=’None’)
Cantidad de objetos de Python representados como un solo objeto de Java:
- sc = pyspark.SparkContext (batchSize=’0’)
Serializador RDD:
- sc = pyspark.SparkContext (serializer=’PickleSerializer()’)
Objeto L{SparkConf} para establecer todas las propiedades de Spark:
- sc = pyspark.SparkContext (conf=’None’)
Usar una puerta de enlace existente y una JVM; de lo contrario, inicialice una nueva JVM:
- sc = pyspark.SparkContext (gateway=’None’)
Instancia de JavaSparkContext:
- sc = pyspark.SparkContext (jsc=’None’)
Se utiliza para generar perfiles (el valor predeterminado es pyspark.profiler.BasicProfiler):
- sc = pyspark.SparkContext (profiler_cls=’<class ‘pyspark.profiler.BasicProfiler’>’)
Nota: los parámetros anteriores, se utilizan class pyspark.SparkContext (master = None) y class pyspark.SparkContext (appName =None), pondremos como ejemplo el que usamos en el post anterior.
- import findspark
- findspark.init()
- import pyspark
- sc = pyspark.SparkContext(master=‘spark://juan-SATELLITE-C55-C-1JM:7077’,appName=‘myspark’)
- sc
. La mayoría de las operaciones o funciones que usamos en Spark provienen de SparkContext, por ejemplo, acumuladores, variables de transmisión, paralelización etc. (solo puede crear un SparkContext por JVM).Solo una SparkContext instancia debe estar activa por JVM. En caso de que desee crear otro SparkContext nuevo, debe detener el Sparkcontext existente (usar stop()) antes de crear uno nuevo.
Recopilando:
Pyspark.SparkContextes es la entrada a la procesos de PySpark que se usa para comunicarse con el clúster y crear un RDD, acumulador y variables de transmisión. La shell PySpark crea y proporciona sc (objeto), que es una instancia de SparkContext. Se puede usar directamente este objeto donde se requiera sin necesidad de crear.
- Referencias: (Entorno-Moreluz)
- Referebcias: PySpark