

Nota: (PySpark es una interfaz (Framework) para Apache Spark diseñado en Python. Podemos escribir aplicaciones Spark utilizando la API-Python, tenemos una Shell-PySpark para analizar de forma interactiva sus datos en un entorno distribuido. La compatibilidad PySpark con la mayoría de las funciones de Spark lo hace un Framework imprescindible. Como: Spark SQL, DataFrame, Streaming, Mllib, Machine-Learning y Spark-Core).
Que es PySpark
-. PySpark es una biblioteca de Spark escrita en Python para ejecutar la aplicación de Python usando las capacidades de Apache Spark, usando PySpark podemos ejecutar aplicaciones en paralelo en el clúster distribuido (múltiples nodos).
-. En otras palabras, PySpark es una API de Python para Apache Spark. Apache Spark es un motor de procesamiento analítico para potentes aplicaciones de aprendizaje automático y procesamiento de datos distribuidos a gran escala.
Recapitulemos sobre Apache-Spark:
Apache-Spark proporciona una interfaz para la programación de clusters completos con Paralelismo de Datos y tolerancia a fallos. Apache Spark se puede considerar un sistema de computación en clúster de propósito general y orientado a la velocidad. Proporciona APIs en Java, Scala, Python y R. Con un motor optimizado que soporta la ejecución de graficos en general. Un conjunto de herramientas de alto nivel entre las que se incluyen Spark SQL (procesamiento de datos estructurados basada) , Mllib (implementar machine learning) , GraphX (procesamiento de graficos) y Spark Streaming. En este post veremos la API en su versión Python lo que es lo mismo PySpark.
-. Spark básicamente escrito en Scala y más tarde debido a su adaptación a la industria, su API PySpark se lanzó para Python usando Py4J. Py4Jes una biblioteca de Java que está integrada en PySpark y permite que python interactúe dinámicamente con objetos JVM, por lo tanto, para ejecutar PySpark también necesita que Java esté instalado junto con Python y Apache Spark.
-. PySpark se utiliza en la comunidad de Ciencia-Datos y Aprendizaje-Automático; hay muchas Bibliotecas-Ciencia-Datos ampliamente utilizadas escritas en Python, incluidas NumPy, TensorFlow. PySpark ejecuta operaciones en miles de millones y billones de datos en clústeres distribuidos 100 veces más rápido que las aplicaciones Python tradicionales.
Las características principales de PySpark.
- -. Cálculo en memoria
- -. Procesamiento distribuido usando paralelizar
- -. Se puede usar con muchos administradores de clústeres (Spark, Yarn, Kubernete, Mesos, etc.)
- -. Tolerante a fallos
- -. Inmutable
- -. Evaluación perezosa
- -. Caché y persistencia
- -. Optimización incorporada al usar DataFrames
- -. Soporta ANSI SQL
PySpark Ventajas
- -. PySpark es un motor de procesamiento distribuido, en memoria y de uso general que le permite procesar datos de manera eficiente y distribuida.
- -. Las aplicaciones que se ejecutan en PySpark son 100 veces más rápidas que los sistemas tradicionales.
- -. Obtendrá grandes beneficios al usar PySpark para canalizaciones de ingesta de datos.
- -. Con PySpark podemos procesar datos de Hadoop HDFS, AWS S3 y muchos sistemas de archivos.
- -. PySpark también se usa para procesar datos en tiempo real usando Streaming y Kafka.
- -. Con la transmisión de PySpark, también puede transmitir archivos desde el sistema de archivos y también desde el socket.
- -. PySpark tiene bibliotecas gráficas y de aprendizaje automático de forma nativa.
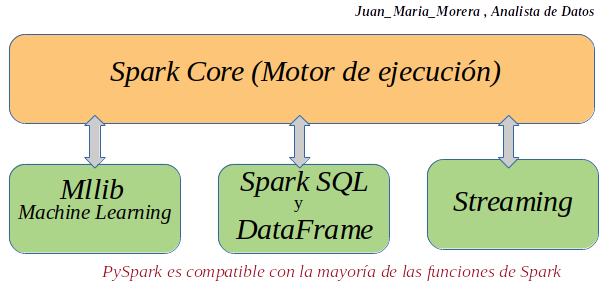
-. Spark SQL and DataFrame: Spark SQL es un módulo de Spark para el procesamiento de datos estructurados. Proporciona una abstracción de programación llamada DataFrame y también puede actuar como un motor de consulta SQL distribuido.
-. Pandas API on Spark: La API de pandas en Spark le permite escalar su carga de trabajo de pandas. Con este paquete podemos.
- Ser inmediatamente productivo con Spark, sin curva de aprendizaje, si ya está familiarizado con los Pandas, es una biblioteca de software escrita como extensión de Numpy para manipulación y análisis de datos para el lenguaje de programación Python.
- Tenga una única base de código que funcione tanto con pandas (pruebas, conjuntos de datos más pequeños) como con Spark (conjuntos de datos distribuidos).
- Cambie a los contextos de la API de pandas y la API de PySpark fácilmente sin sobrecarga.
-. Streaming: Ejecutándose sobre Spark, la función de Streaming en Apache Spark permite potentes aplicaciones interactivas y analíticas tanto en transmisión como en datos históricos, al tiempo que hereda la facilidad de uso y las características de tolerancia a fallas de Spark.
-. Mllib: Construido sobre Spark, MLlib es una biblioteca de aprendizaje automático escalable que proporciona un conjunto uniforme de API de alto nivel que ayudan a los usuarios a crear y ajustar canalizaciones prácticas de aprendizaje automático.
-. Spark Core: Spark Core es el motor de ejecución general subyacente para la plataforma Spark sobre el que se construyen todas las demás funciones. Proporciona un RDD (Conjunto de datos distribuido resistente) y capacidades informáticas en memoria.
Recapitulando:
Un resumen de interfaz PySpark para Apache Spark, sus aracterísticas principales, sus ventajas y las Funciones de Spark compatibles con PySpark.
- Referencias: (Entorno-Moreluz)
- Referencias: Para-saber-mas
- Referencias: PySpark