

Nota: En este post procederemos a la instalación en my-portatil en un entorno virtual de Python-venv de esta forma creamos marco-trabajo-aislado, sencillo de utilizar y evitamos cargar nuestro entorno de trabajo de cosas que usamos puntualmente. En el cual Instalar-Spark-Modo-Standalone con jupyter-notebook.
Entorno virtual de Python (VENV)
Nota: Crear otro entornos de Python ya que se puede crear todos los que necesitemos en este caso lo llamareos (pyspark) en los que se puede instalar cualquier módulo de Python sin «perturbar» el sistema principal u otros entornos como el que he usado para probar las (bibliotecas-Python) .
Creamos la carpeta pyspark:
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# mkdir pyspark
Creamos el proyecto (PySpark) :
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# python3.6 -m venv pyspark
Activar el entorno :
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# source pyspark/bin/activate
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv#
Actualizamos pip:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# python -m pip install –upgrade pip
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# pip –version
- Out: pip 21.3.1 from /my-venv/jupyter/lib/python3.6/site-packages/pip (python 3.6)
Instalamos la Aplicación:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# pip install jupyter
Arrancar Jupyter :
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# jupyter notebook –allow-root –no-browser
Recordar para desactivar un entorno virtual de Python :
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# deactivate
Nota: la instalacion de Spark puede ser compleja. Tenemos el formato de aplicaciones Spark se puede hacer en varios idiomas y cada uno se instala forma diferente. La API subyacente para Spark está escrita en Scala, pero PySpark es una API superpuesta para la implementación en Python. Para las aplicaciones de ciencia de datos, es recomendable el uso de PySpark y Python en lugar de Scala. Scala es más fácil de implementar pero es aconsejable instalar PySpark.
Instalar-Spark-Modo Standalone
Nota: Spark Standalone (Cluster Spark Nativo) este modo utilizado solo para pruebas o en entornos de desarrollo donde el almacenamiento distribuido no es obligatorio y se puede usar el sistema de archivos local. En un escenarion como este, Spark se ejecuta en una única máquina con un executor por cada core de CPU. Lo primero es activar el entorno virtual de Python-venv que creamos anteriormente (pyspark) y procederemos a la instalacion de Spark.
Nota: Una sencilla utilidad de Python que se puede utilizar para descargar e instalar un JDK o JRE de Java determinado, es una biblioteca de Java que está integrada en PySpark y permite que python interactúe dinámicamente con objetos JVM, por lo tanto, para ejecutar PySpark también necesita que Java esté instalado junto con Python y Apache Spark. Pero necesitamos que java este en el Linux de my-portatil.
Instalar Java en linux:
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv/pyspark/spark# apt install openjdk-8-jre-headless
- In: root@juan-SATELLITE-C55-C-1JM:/# java -version
- Out: openjdk version «1.8.0_342» OpenJDK Runtime Environment (build 1.8.0_342-8u342-b07-0ubuntu1~18.04-b07) OpenJDK 64-Bit Server VM (build 25.342-b07, mixed mode)
Descarga Spark:
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# curl -O https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
Descomprimir el fichero.tgz
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# tar xvf spark-3.1.1-bin-hadoop3.2.tgz
- Out: spark-3.1.1-bin-hadoop3.2
Mover la carpeta y renombra la carpeta a pyspark/spark :
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# mv spark-3.1.1-bin-hadoop3.2// pyspark/spark
Nota: Descargamos Spark de Apache.org, lo descomprimimos viene en un fichero .tgz , lo movemos a la carpeta del proyecto (PySpark) my-venv/pyspark y esta carpeta (spark-3.1.1-bin-hadoop3.2) la renombramos a apark nos facilita las cosas cuando trabajamos con ello.
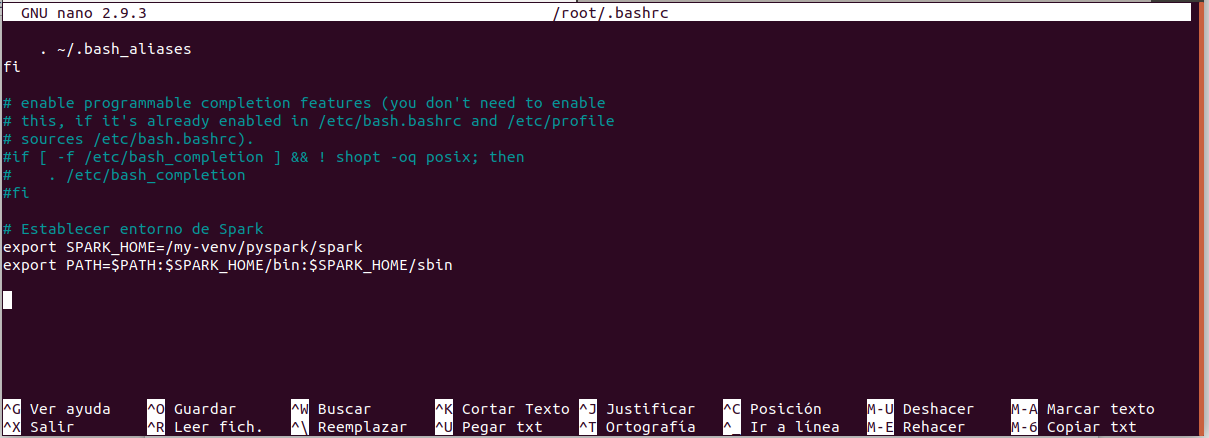
Nota: Establecer entorno de Spark, lo primero creamos un enlace simbólico y a continuacion editamos con nano el archivo de configuración de bashrc y agregamos las dos lineas al final de testo existente, salvamos y activa los cambios.
Crea un enlace simbólico:
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# ln -s /my-venv/pyspark/spark
Editar el archivo de configuración de bashrc :
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# nano ~/.bashrc
- export SPARK_HOME=/my-venv/pyspark/spark
- export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Activa los cambios del fichero bashrc:
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# source ~/.bashrc
Activar el entorno Venv-pyspark :
- In: root@juan-SATELLITE-C55-C-1JM:/my-venv# source pyspark/bin/activate
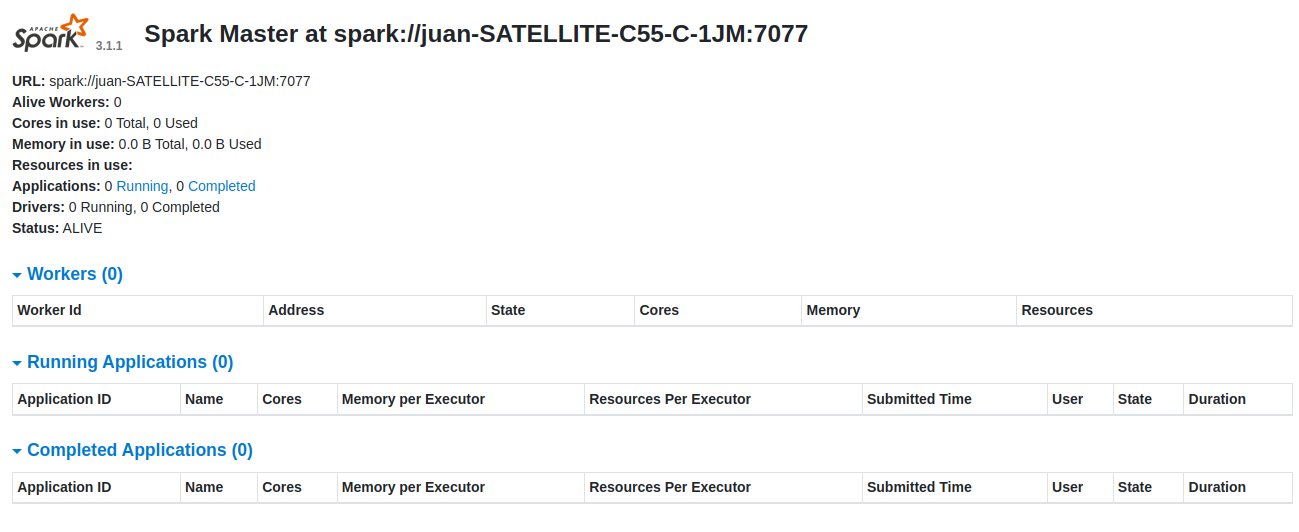
Nota: Arrancamos Spark en modo Standalone es decir se ejecuta sus nodos Master y Worker en Host y como detenerlos.
Arrancamos el Master:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# ./spark/sbin/start-master.sh
- Out: starting org.apache.spark.deploy.master.Master, logging to /my-venv/pyspark/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-juan-SATELLITE-C55-C-1JM.out
Para detener el Master :
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# ./spark/sbin/stop-master.sh
- Out: no org.apache.spark.deploy.master.Master to stop
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv#
Nota: Acceder a la interfaz web de Spark usando la URL en nuestro navegador web http://127.0.0.1:8080/
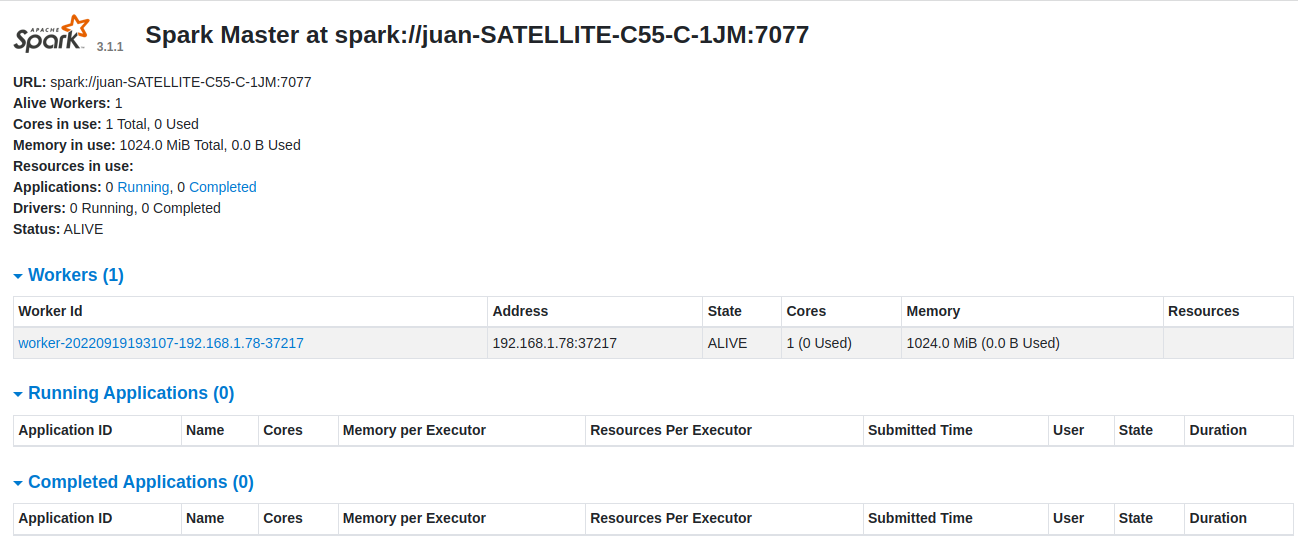
Arrancamos un Worker necesitamos URL: spark://juan-SATELLITE-C55-C-1JM:7077
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# ./spark/sbin/start-worker.sh -c 1 -m 1024M spark://juan-SATELLITE-C55-C-1JM:7077
- Out: starting org.apache.spark.deploy.worker.Worker, logging to /my-venv/pyspark/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-juan-SATELLITE-C55-C-1JM.out
Detener el Worker :
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# ./spark/sbin/stop-worker.sh -c 1 -m 1024M spark://juan-SATELLITE-C55-C-1JM:7077
- Out: no org.apache.spark.deploy.worker.Worker to stop
Nota: Spark dashboard (Interfaz-Spark) y actualice la pantalla y tenemos el nuevo proceso de trabajo de Spark en la siguiente pantalla:
Instalamos PySpark:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# pip install pyspark
Ejecutamos PySpark:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# pyspark
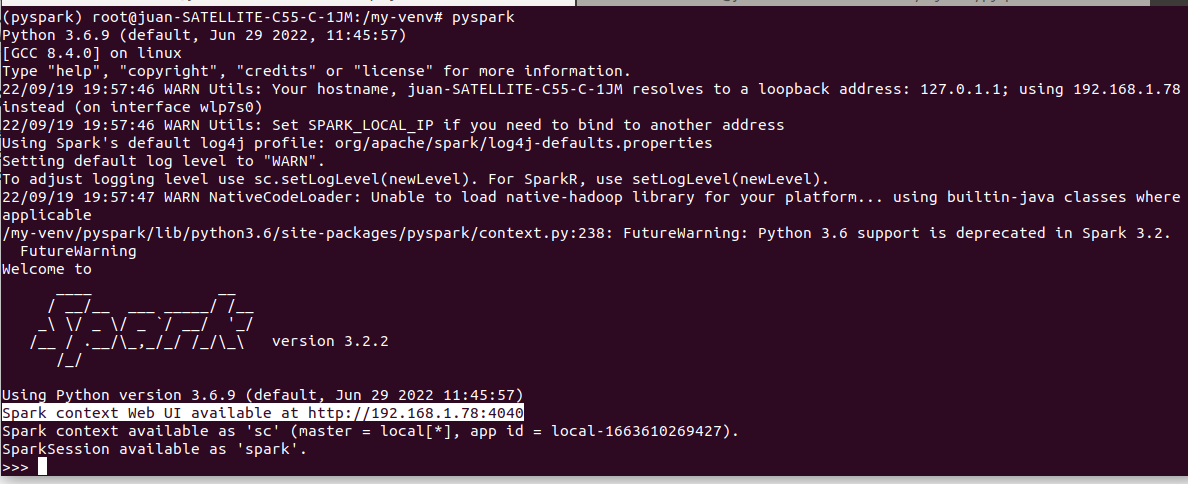
Nota: para salir >>> exit() , en esta pantalla del terminal tenemos la dirección de Interfaz de usuario de la aplicación PySparkShell (Trabajos de Spark). http://192.168.1.78:4040/jobs/ para mantener esta Interfaz de usuario tenemos que tener en (ejecución PySpark).
Instalar findpark:
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# pip install findspark
- Collecting findspark
- Downloading findspark-2.0.1-py2.py3-none-any.whl (4.4 kB)
- Installing collected packages: findspark
- Successfully installed findspark-2.0.1

Arrancar Jupyter :
- (pyspark) root@juan-SATELLITE-C55-C-1JM:/my-venv# jupyter notebook –allow-root –no-browser
Nota: usare pata arrancar la (Interfaz-Jupyter) http://127.0.0.1:8888/?token=4b29adb5509f23d28113606e7fc6de662a195ab52e0030a9
Copiar en jupyter:
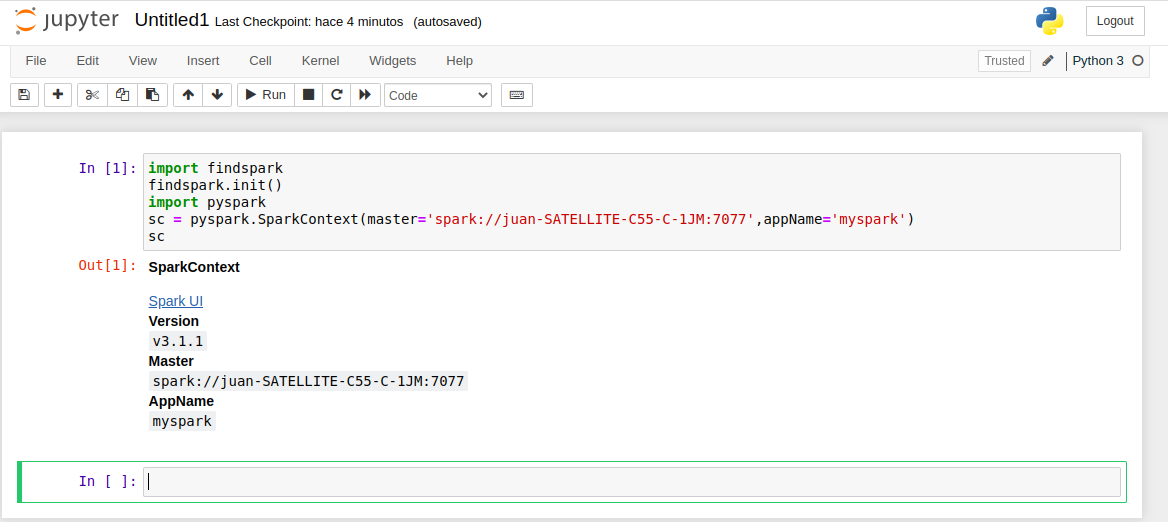
- import findspark
- findspark.init()
- import pyspark
- sc = pyspark.SparkContext(master=‘spark://juan-SATELLITE-C55-C-1JM:7077‘,appName=‘myspark‘)
- sc
Nota: le damos la orden de importar findspark y pyspark el próximos post explicare en detalle pyspark la Out:Spark UI Version v3.1.1 Master spark://juan-SATELLITE-C55-C-1JM:7077 AppName myspark lo cual nos confirma su funcionalidad
Recopilando :
Realizamos la instalación en my-portatil en un entorno virtual de Python-venv en el cual Instalar-Spark-Modo-Standalone con jupyter-notebook, aclaración referente al Worker en este modo solo podemos tener uno, -c 1 -m 1024M significa un nucleo 1mega de memoria esto podemos poner lo que queramos, pero en producción cuantos mas nodos mejor y cuando digo mas puedo referirme a Miles, La palabra mágica es Paralelizar .
Referencias: Entorno-Moreluz