

Nota: En este laboratorio de Apache-Spark y Docker y controlando por PySpark , Jupyter-Notebook, su objetivo es poner en funcionalidad diferentes programas para conseguir un entorno de producción.
- -.Estos Apuntes se basan en un laboratorio (Que iré escalando) de Apache-Spark y Docker y controlando por PySpark , Jupyter-Notebook .
- -.Probando diferentes configuraciones de Pytho-Venv , Docker ,en Cluster etc. En esta ocasión usare un portátil Host el cual ejecuta sus nodos Master y Worker en Host ,es decir modo Standalone .
- -.Tenemos un entorno virtual Python3.6-Venv , ya creado anteriormente como un ecosistema con Apache-Spark , PySpark , Jupyter .
Levantamos entorno virtual venv (Activate)-(Deactivate) :
- In: root@juan-Aspire-ES1-512:/# source my_pyspark/bin/activate
- In: (my_pypark) root@juan-Aspire-ES1-512:/# deactivate
-. Nota:Arrancamos Spark en modo Standalone es decir se ejecuta sus , nodos Master y (aunque el Worker se encuentre un contenedor Docker ) esta en el Host
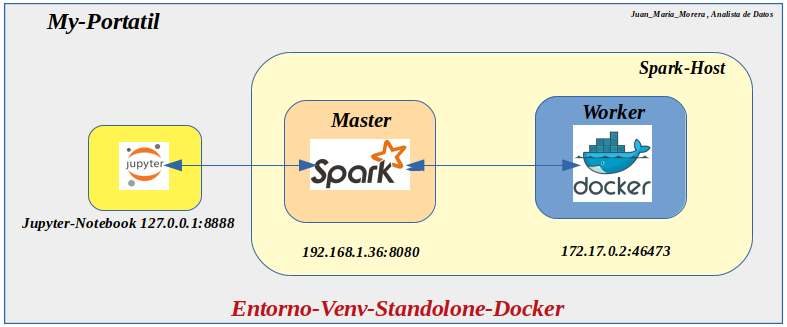
Arrancamos Spark en modo Standalone:
- In: (my_pyspark) root@juan-Aspire-ES1-512:/# ./spark/sbin/start-master.sh -h 192.168.1.36
- Out: starting org.apache.spark.deploy.master.Master, logging to /my_pyspark/spark/logs/spark-root org.apache.spark.deploy.master.Master-1-juan-Aspire-ES1-512.out
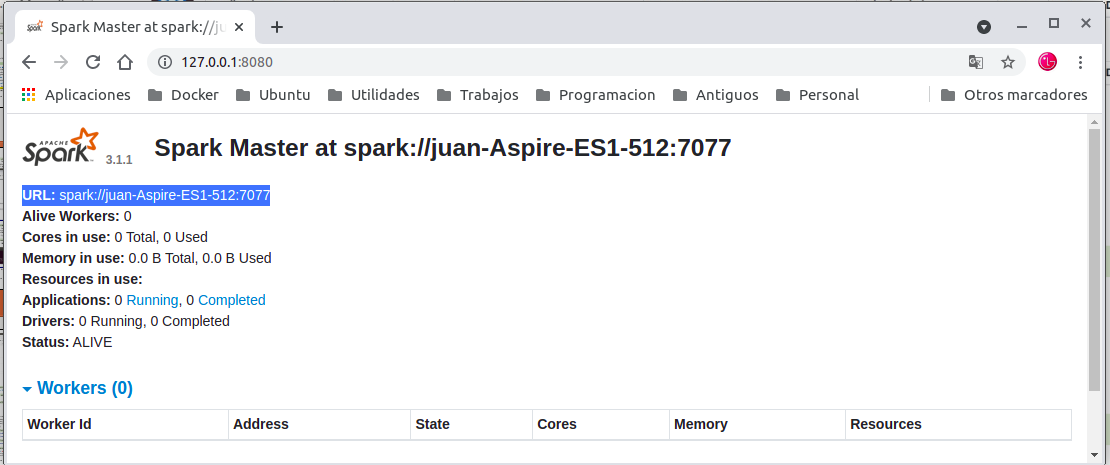
http://127.0.0.1:8080/
-. Creamos el contenedor Docker tenemos diferentes formas de abordar el tema , usar una imagen del repositorio oficial de Docker , usar o crear un Dockerfile o hacerlo manualmente nosotros usaremos esta ultima.
Crear un contenedor docker:
- In: root@juan-Aspire-ES1-512:/# docker run -it –name spark_docker -m 1024M –cpus 1 ubuntu
- In: root@c59e3ef5557f:/#
Deshabilitar el modo interactivo: ¿para que no pregunte?
- In: root@c59e3ef5557f:/# export DEBIAN_FRONTEND=noninteractive
Instalar las dependencias(Java, Python y Nano)
- In: root@c59e3ef5557f:/# apt update && apt install -y openjdk-8-jdk python nano
Descarga Spark:(descomprimir el fichero.tgz)-(crear)Mover a la carpeta /spark
- In: root@juan-Aspire-ES1-512:/# curl -O https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1- bin-hadoop3.2.tgz
- In: root@juan-Aspire-ES1-512:/# tar xvf spark-3.1.1-bin-hadoop3.2.tgz
Copiar el paquete entero de Apache Spark <ID_CONTENEDOR> /opt del cotenedor
- In: root@juan-Aspire-ES1-512:/# docker cp spark-3.1.1-bin-hadoop3.2 c59e3ef5557f:/opt
Renombra Carpeta :
- In: root@c59e3ef5557f:/opt# mv spark-3.1.1-bin-hadoop3.2 spark
Crea un enlace simbólico:
- In: root@c59e3ef5557f:/opt# ln -s /opt/spark/sbin
Establecer entorno de Spark:(Abra su archivo de configuración de bashrc)Activa los cambios
- In: root@1bf0b87d3b85:/# nano ~/.bashrc
- export SPARK_HOME=/opt/spark
- export PATH=$SPARK_HOME/bin:$PATH
- In: root@1bf0b87d3b85:/# source ~/.bashrc
Arrancamos el worker sintuado en Contenedor-Docker :
- In: root@1bf0b87d3b85:/opt# ./spark/sbin/start-worker.sh spark://192.168.1.36:7077
- Out: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark–org.apache.spark.deploy.worker.Worker-1-1bf0b87d3b85.out
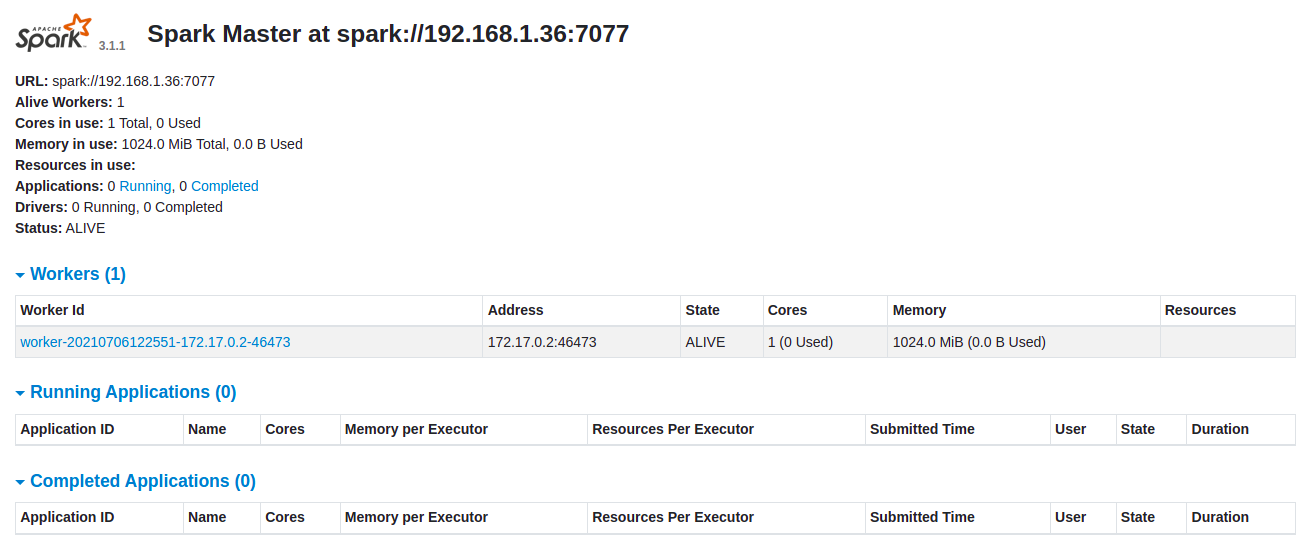
Nota: Ahora veremos en Spark-Master el Worker activo con su ID , Address 172.17.0.2:46473 este puerto habrá que asignarle un puerto fijo y vemos los recursos usados por el Worker .
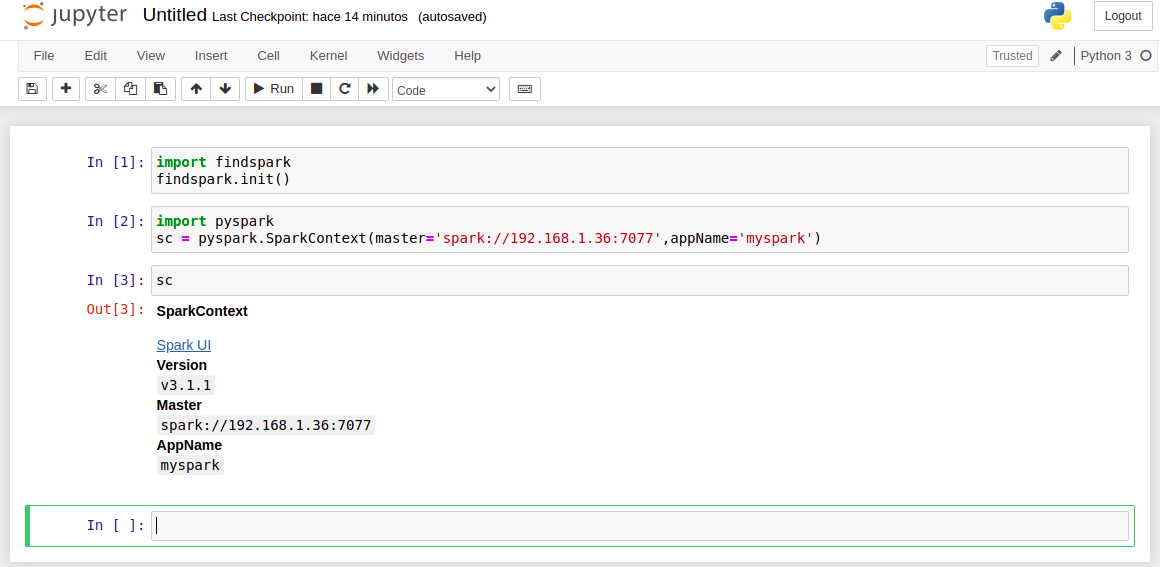
Arrancamos un Jupyter-Notebook :
- In: (my_pyspark) root@juan-Aspire-ES1-512:/# jupyter notebook –allow-root

http://localhost:8888/?token=17cafcaaad4e02e72275b1332a26fed7334588b6df7e3c92 Recomiendo cortar-pegar en nuestro navegador en ciertas ocasiones e tenido algún problema
Crear una aplicación Spark y comenzar: pegando el siguiente script en una celda de Jupyter
- In: import findspark
- findspark.init()
- In: import pyspark
- sc = pyspark.SparkContext(master=’spark://192.168.1.36:7077′,appName=’myspark’)
- In: sc
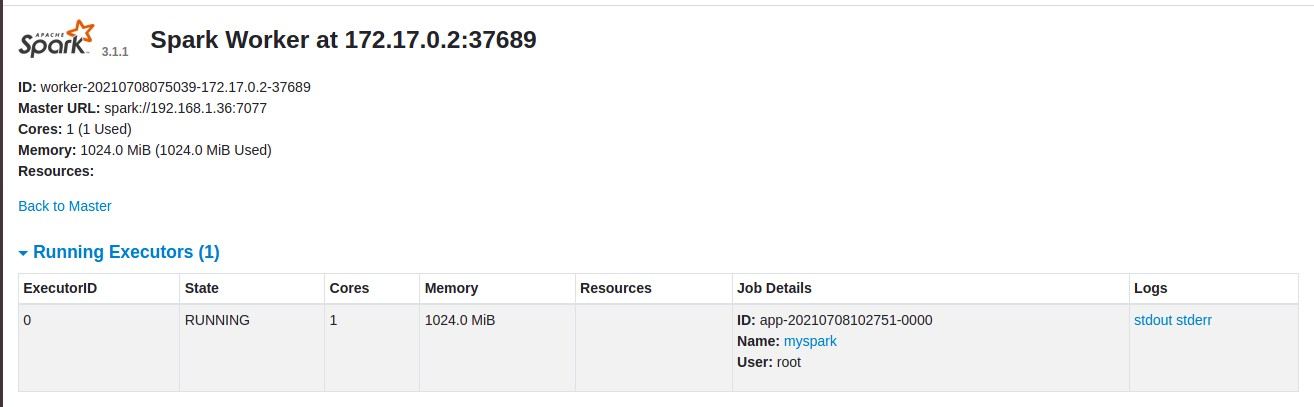
Nota: En el Spark Worker situado en el Contenedor-Docker vemos la ejecución de nuestro script , por-tanto esta (Running) , ID: worker-20210708075039-172.17.0.2-37689
Consola PySpark , Web UI available at http://192.168.1.36:4040
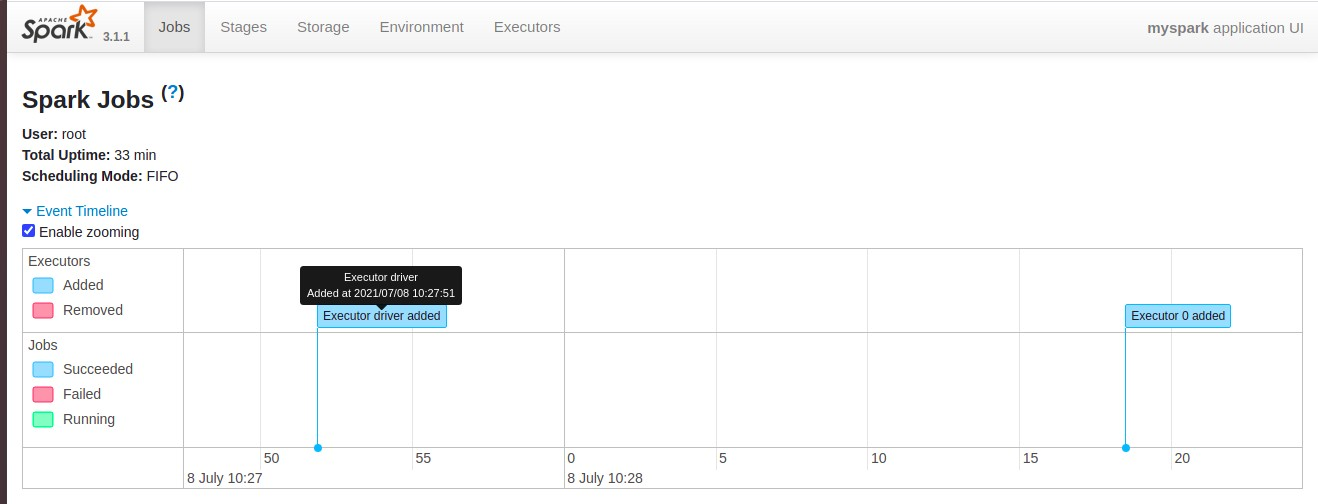
Nota:192.168.1.36:4040 como vemos y arrancado la Consola PySpark en nuestro Jupyter hemos dado la orden de(import pyspark) , arrancamos (SparkContext) , perdón tenia que usar (SparkSesaion) ,para probar Vale .
Recapitulando :
- Activamos el entorno virtual Python3.6-Venv , activamos el (start-master.sh) en el Host .
- En nuestro contenedor Docker activamos el Worker situado en el Host (start-worker.sh) .
- En nuestro navegador Wed http://127.0.0.1:8080/ el cual nos dara la URL: spark://192.168.1.36:7077 y información de nuestros worker y recurso de nuestro entorno .
- Arrancaremos nuestra IDE favorita en mi caso Jupyter-Notebook , import findspark y pyspark y ejetutamos un pequeño script para confirmar la interacciona con Spark a traves de API-PySpark lo cual podemos comprobar en Spark context Web UI available at http://192.168.1.36:4040
- Con todo esto usar Docker y Python-Venv se trata de aislar todos estos procesos de la maquinas Host o Server se notara mucho cuando escalemos el proceso con la cleacion de cluster .
Este laboratorio fue creado en el (Entorno-Moreluz)