

Nota: Que hace un optimizador de API-Keras, obviamente, optimizar los valores de los parámetros para reducir el error cometido por la Red-Neuronal. El proceso mediante el cual se hace esto se conoce como: Propagación hacia atrás de errores o Retropropagación & Backpropagation es un método común para entrenar Redes-Neuronales-Artificiales .
Optimizadores
-. Un Optimizador es uno de los dos argumentos necesarios para compilar un Modelo de API–Keras, usaremos compile() y fit().
-. Empecemos por su configuración, realicemos un reseteo y carguemos las librerías.
Reseteo:
- In: import tensorflow as tf
- In: tf.keras.backend.clear_session()
Librerías:
- In: import tensorflow as tf
- In: from tensorflow import keras
- In: from keras import layers
Llamar-Instancia:
- model = keras.Sequential()
- model.add(layers.Dense(64, kernel_initializer=‘uniform’, input_shape=(10,)))
- model.add(layers.Activation(‘softmax’))

Llamar-Optimizador:
- opt = keras.optimizers.Adam(learning_rate=0.01)
- model.compile(loss=‘categorical_crossentropy’, optimizer=opt)

Optimizador de identificador de cadena: “Este utiliza los parámetros por defecto del optimizador”.
In: model.compile(loss=‘categorical_crossentropy’, optimizer=‘adam’)

Entrenamiento-Personalizado
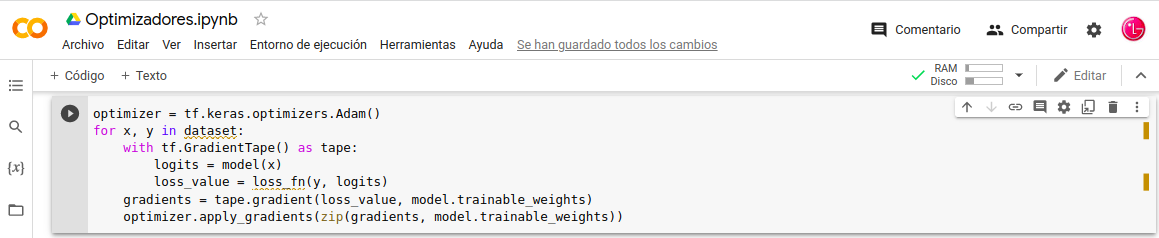
-. Consideremos un ciclo de Entrenamiento–Personalizado, a través de la instancia tf.GradientTape recuperaría gradientes. Posteriormente llamamos al optimizer.apply_gradients() lo cual actualizar los Pesos.
Crear-Instancia-Optimizador:
- In: optimizer = tf.keras.optimizers.Adam()
Ejecutemos los Procesos:
- In: for x, y in dataset:
- In: with tf.GradientTape() as tape:
- In: logits = model(x)
- In: loss_value = loss_fn(y, logits)
Gradientes de Pérdida los pesos:
- In: gradients = tape.gradient(loss_value, model.trainable_weights)
Actualizar los Pesos del Modelo:
- In: optimizer.apply_gradients(zip(gradients, model.trainable_weights))
Nota: Tenemos que tener en cuenta que este objeto no tenemos in dataset por lo tanto tampoco los loss_fn si los procesamos nos da error.
Relación de Optimizadores disponibles:
- USD
- RMSprop
- Adán
- AdánW
- Adadelta
- Adagrado
- Adamax
- adafactor
- Nadam
- Ftrl
API del Optimizador principal:
-. Estos métodos y atributos que estamos usando son comunes a todos los Optimizadores de Keras.
El método apply_gradients :
- Optimizer.apply_gradients(
- grads_and_vars, name=None, skip_gradients_aggregation=False, **kwargs
- )

Argumentos:
- grads_and_vars : Lista de “gradient, variable” pares.
- nombre : cadena, por defecto es Ninguno. El nombre del ámbito de nombres que se usará al crear variables. Si no hay, “self.name” se utilizará.
- skip_gradients_aggregation : si es verdadero, la agregación de gradientes no se realizará dentro del optimizador. Por lo general, este argumento se establece en True cuando escribe código personalizado agregando gradientes fuera del optimizador.
- **kwargs : argumentos de palabra clave solo utilizados para compatibilidad con versiones anteriores.
Recopilando:
Hemos visto el Optimizador es uno de los dos argumentos para compilar un Modelo de API-Keras.
- Referencias: (Entorno-Moreluz)
- Referencias: (Keras)