

Nota: (Keras-Applications: son módulo de aplicaciones de el Frameworks de Deep-Learning de API-Keras. Nos proporciona definiciones de Modelos y Pesos preentrenados para varias arquitecturas en este caso usaremos el Modelo-EfficientNet).
Qué es EfficientNet
-. EfficientNet, se encuentra entre los modelos más eficientes, requiere menos FLOPS para la inferencia que alcanza una precisión excelente, tanto en imagenet como en tareas de aprendizaje de transferencia de clasificación de imágenes comunes.
¿Que son FLOPS?: Usamos el término FLOPS para medir la cantidad de operaciones de una red de Deep-Learning, numero de “operaciones de punto flotante por segundo”, los FLOPs nos darán la complejidad de nuestro modelo.
¿Que son Inferencia?: la inferencia consiste en poner en práctica lo que la Red-neuronal-Artificial ha aprendido en el entrenamiento.
-. EfficientNet proporciona una familia de Modelos (B0 a B7) que representa una buena combinación de eficiencia y precisión en una variedad de escalas. Permite que el Modelo base orientado a la eficiencia (B0) supere los Modelos en todas las escalas, al tiempo que evita la búsqueda extensiva de hiperparámetros en la cuadrícula. En definitiva usaremos EfficientNet con pesos preentrenados en imagenet para la clasificación de Dataset-Stanford Dogs.
Implementación-Keras-EfficientNet
-. Creamos una implementación de EfficientNet B0 a B7 con Keras. Para usar EfficientNetB0 para clasificar 1000 clases de imágenes de imagenet,
- In: from keras.applications import EfficientNetB0
- In: model = EfficientNetB0(weights=‘imagenet’)
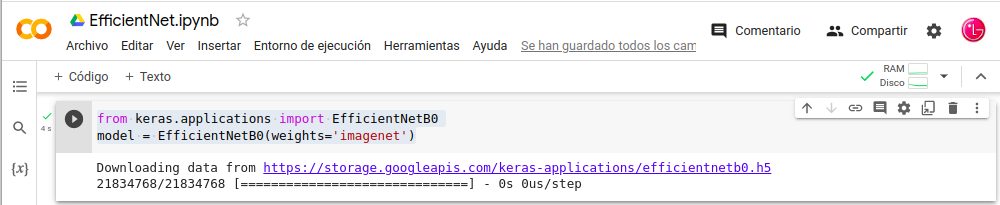
- Este Modelo toma imágenes de entrada de forma (224, 224, 3)
- Los Datos de entrada deben oscilar entre [0, 255].
- La normalización se incluye como parte del modelo.
-. Entrenar EfficientNet con ImageNet requiere una gran cantidad de recursos y varias técnicas que no forman parte de la arquitectura del Modelo. La implementación de Keras carga por defecto pesos preentrenados obtenidos a través del entrenamiento con AutoAugment .
¿Que es AutoAugment? El aumento de datos es una técnica eficaz para mejorar la precisión de los clasificadores de imágenes .
-. Para los Modelos base B0 a B7, las formas de entrada son diferentes.
Formas de entrada para cada modelo:
- modelo base resolución
- EfficientNetB0 224
- EfficientNetB1 240
- EfficientNetB2 260
- EfficientNetB3 300
- EfficientNetB4 380
- EfficientNetB5 456
- EfficientNetB6 528
- EfficientNetB7 600
¿ Que es Stanford Dogs?: este conjunto de datos contiene imágenes de 120 razas de perros de todo el mundo, el conjunto de datos se ha creado utilizando imágenes y anotaciones de ImageNet.
¿ Que es ImageNet?: es un gran conjunto de datos de fotografías anotadas destinadas para computadora Investigación de la visión.
-. Si el Modelo está destinado a la transferencia de aprendizaje, tenemos que eliminar las capas superiores. Keras ofrece una opción para eliminarlas.
Eliminar- Layers superiores:
In: model = EfficientNetB0(include_top=False, weights=‘imagenet’)
¿ Que es Stanford Dogs?: este conjunto de datos contiene imágenes de 120 razas de perros de todo el mundo, el conjunto de datos se ha creado utilizando imágenes y anotaciones de ImageNet.
¿ Que es ImageNet?: es un gran conjunto de datos de fotografías anotadas destinadas para computadora Investigación de la visión.
-. Si el Modelo está destinado a la transferencia de aprendizaje, tenemos que eliminar las capas superiores. Keras ofrece una opción para eliminarlas.
Eliminar- Layers superiores:
- In: model = EfficientNetB0(include_top=False, weights=‘imagenet’)

-. El argumento drop_connect_rate controla la tasa de abandono de la profundidad estocástica. Al constructor del Modelo sirve como interruptor para la regularización adicional en el ajuste fino, no afecta los pesos cargados. El valor predeterminado es 0,2 en este caso usaremos 0,4.
Cambiar la profundidad estocástica:
- In: model = EfficientNetB0(weights=‘imagenet’, drop_connect_rate=0.4)

Determinado por EfficientNetB0:
- In: IMG_SIZE = 224

Cargar-Datasets
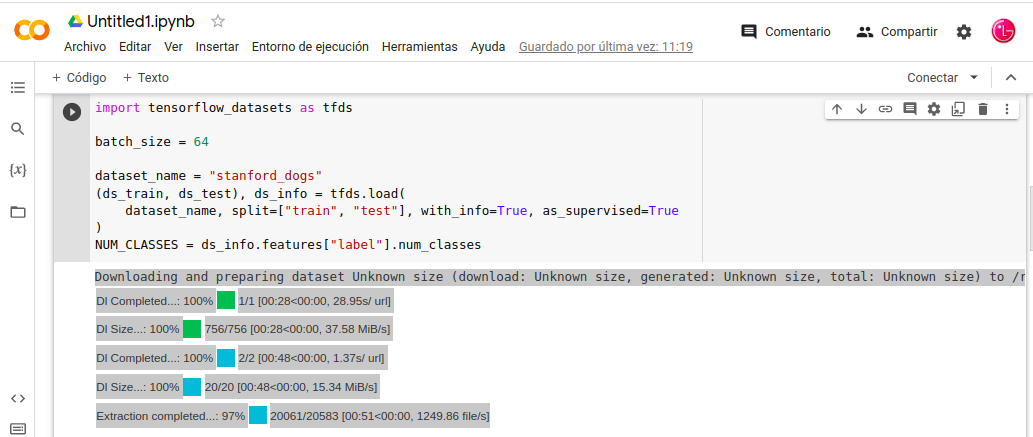
-. Procedemos a la carga del datasets “tfds”, el conjunto de datos stanford_dogs . Si queremos cambiar el conjunto de datos lo haríamos con dataset_name, podria usar los datos “tfds” como cifar10 , cifar100 , food101 , etc. para conjuntos de datos pequeños, puede intentar cargar datos en la memoria y usar tf.data.Dataset.from_tensor_slices().
Cargamos el Dataset:
- In: import tensorflow_datasets as tfds
- In: batch_size = 64
- In: dataset_name = «stanford_dogs»
- In: (ds_train, ds_test), ds_info = tfds.load(
- In: dataset_name, split=[«train», «test»], with_info=True, as_supervised=True
- In: )
- In: NUM_CLASSES = ds_info.features[«label»].num_classes
-. Los Datasets incluye imágenes con varios tamaños, tenemos que cambiar su tamaño a un tamaño compartido para todas las imágenes, cambiamos el tamaño de las imágenes al tamaño de entrada necesario para EfficientNet. Cual es “IMG_SIZE = 224” para EfficientNetB0.
Cambiar-Tamaño–Imágenes:
- In: size = (IMG_SIZE, IMG_SIZE)
- In: ds_train = ds_train.map(lambda image, label: (tf.image.resize(image, size), label))
- In: ds_test = ds_test.map(lambda image, label: (tf.image.resize(image, size), label))

Visualizan-Datos
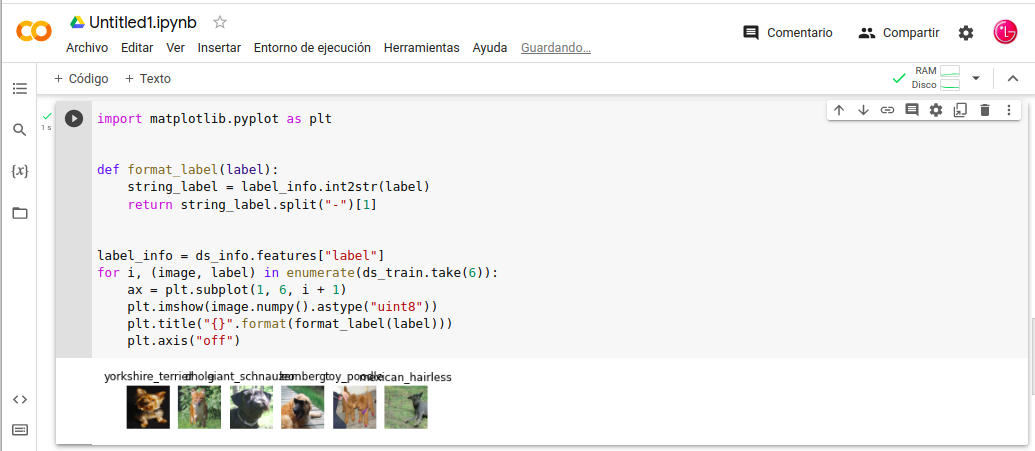
-. Pasemos a la parte de la visualización de datos la imágenes con la librería matplotlib en la cual podemos elegir el numero imágenes con sus etiquetas.
Visualizar las imágenes:
- In: import matplotlib.pyplot as plt
- In: def format_label(label):
- In: string_label = label_info.int2str(label)
- In: return string_label.split(«-«)[1]
- In: label_info = ds_info.features[«label»]
- In: for i, (image, label) in enumerate(ds_train.take(6)):
- In: ax = plt.subplot(1, 6, i + 1)
- In: plt.imshow(image.numpy().astype(«uint8»))
- In: plt.title(«{}».format(format_label(label)))
- In: plt.axis(«off»)
Aumento de Datos
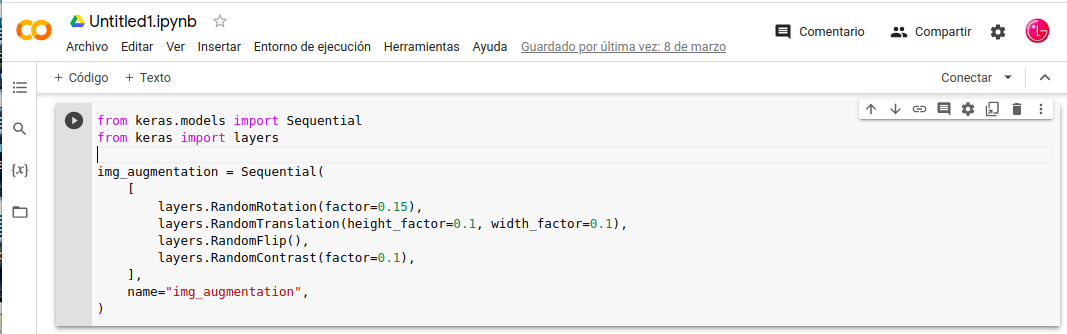
-. Para este aumento de datos Podemos usar las API-Layers con un Modelo-Sequential de preprocesamiento para el aumento de imágenes.
- In: from keras.models import Sequential
- In: from keras import layers
- In: img_augmentation = Sequential(
- In: [
- In: layers.RandomRotation(factor=0.15),
- In: layers.RandomTranslation(height_factor=0.1, width_factor=0.1),
- In: layers.RandomFlip(),
- In: layers.RandomContrast(factor=0.1),
- In: ],
- In: name=«img_augmentation»,
- In: )
-. Este Modelo-Sequential que usamos para el aumento de datos podemos usar como parte del Modelo que generamos a continuación o como una función para preprocesar datos antes de introducirlos en el Modelo.
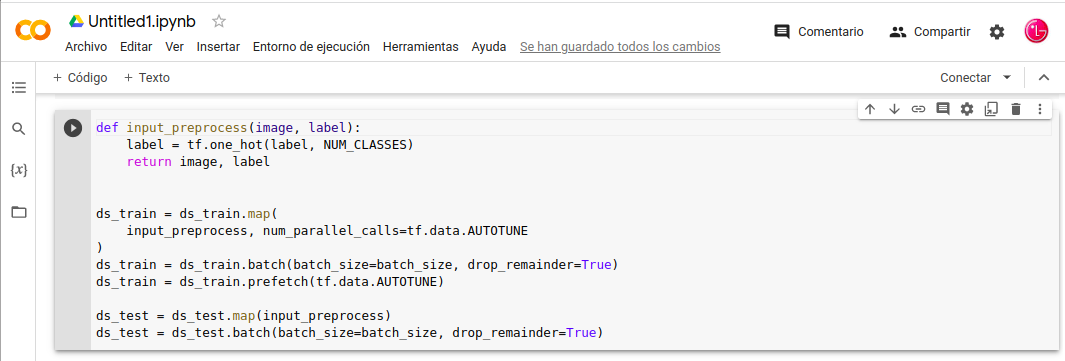
Preparar-Datos-Entrenamiento
-. Tenemos los datos de entrada verificados y el aumento funcionan esta correcto, preparamos el conjunto de datos para el entrenamiento.
- Los datos de entrada se redimensionan a uniforme IMG_SIZE.
- Las etiquetas “categórica” se colocan en codificación one-hot .
- El conjunto de datos se procesa por lotes.
Preparar los Datos:
- In: def input_preprocess(image, label):
- In: label = tf.one_hot(label, NUM_CLASSES)
- In: return image, label
- In: ds_train = ds_train.map(
- In: input_preprocess, num_parallel_calls=tf.data.AUTOTUNE
- In: )
- In: ds_train = ds_train.batch(batch_size=batch_size, drop_remainder=True)
- In: ds_train = ds_train.prefetch(tf.data.AUTOTUNE)
- In: ds_test = ds_test.map(input_preprocess)
- In: ds_test = ds_test.batch(batch_size=batch_size, drop_remainder=True)
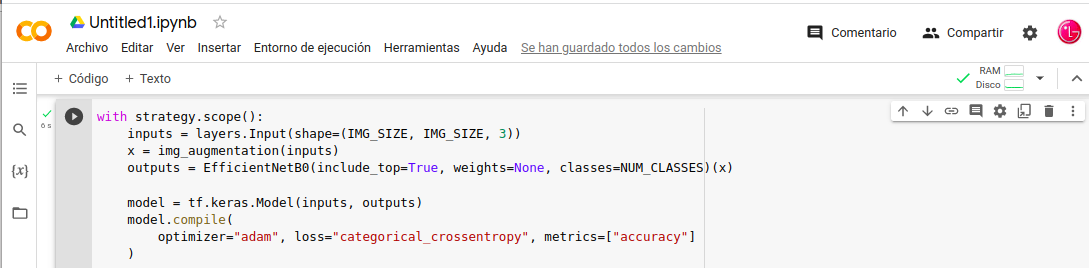
Primera Opción Entrenar-Modelo (desde cero)
- In: with strategy.scope():
- In: inputs = layers.Input(shape=(IMG_SIZE, IMG_SIZE, 3))
- In: x = img_augmentation(inputs)
- In: outputs = EfficientNetB0(include_top=True, weights=None, classes=NUM_CLASSES)(x)
- In: model = tf.keras.Model(inputs, outputs)
- In: model.compile(
- In: optimizer=«adam», loss=«categorical_crossentropy», metrics=[«accuracy»]
- In: )
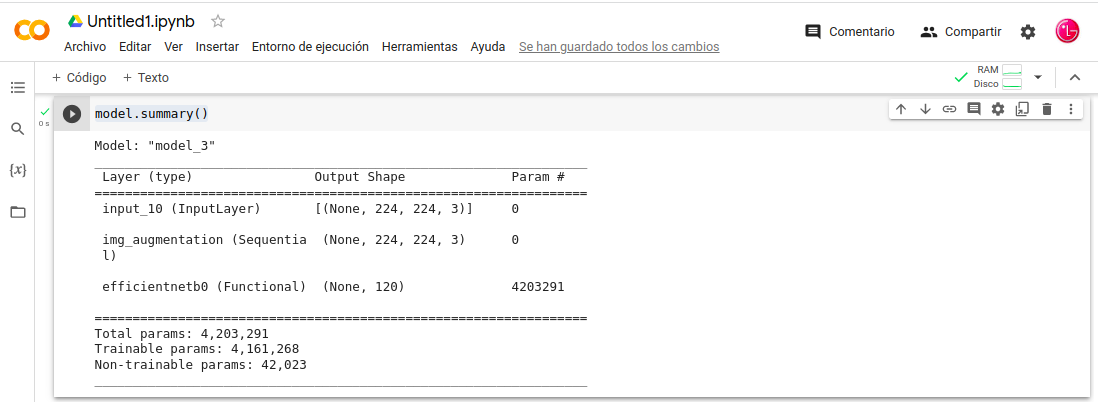
In: model.summary()
epochs = 40 # @param {type: «slider», min:10, max:100}
hist = model.fit(ds_train, epochs=epochs, validation_data=ds_test, verbose=2)

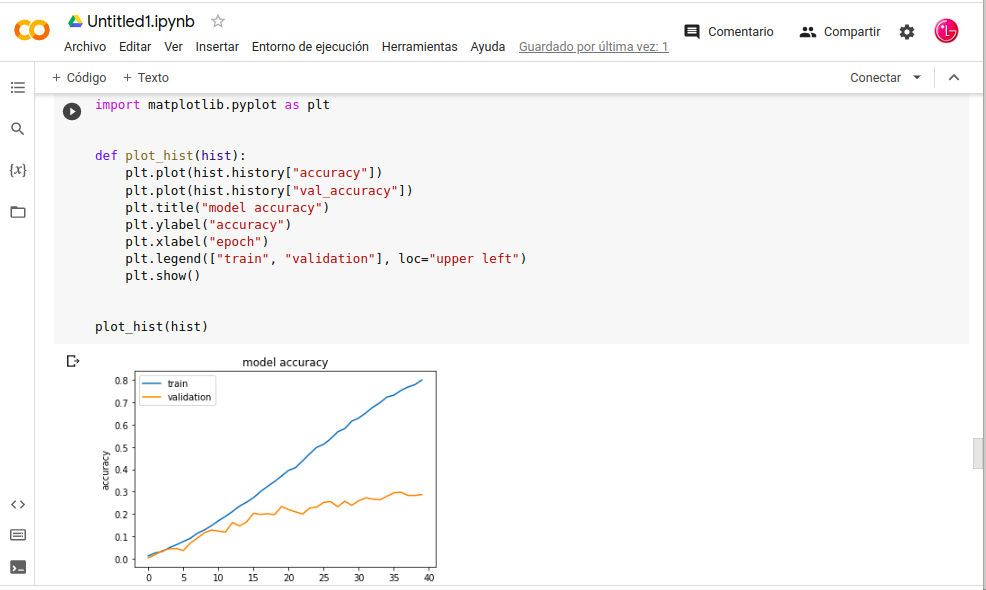
-. El entrenamiento de Modulo-Aplicación-keras pasamos una tasa de aprendizaje 40epochs con Google-Colaboratory, en la imagen siguiente podemos ver tiempo de procesamiento y configuración y tenemos que tener en cuenta que estamos usando la versión gratuita.

. El entrenamiento desde cero, necesita selección cuidadosa de los hiperparámetros y no es fácil es encontrar la regularización necesaria. Los recursos sería muchos más exigente. La precisión del entrenamiento la validación, la precisión de la validación se estanca en un valor bajo.
¿Que es hiperparámetros? ; Los hiperparámetros de un modelo son los valores de las configuraciones utilizadas durante el proceso de entrenamiento, son los que el usuario define explícitamente para controlar el proceso de aprendizaje.
Visualicemos esto:
In: import matplotlib.pyplot as plt
In: def plot_hist(hist):
In: plt.plot(hist.history[«accuracy»])
In: plt.plot(hist.history[«val_accuracy»])
In: plt.title(«model accuracy»)
In: plt.ylabel(«accuracy»)
In: plt.xlabel(«epoch»)
In: plt.legend([«train», «validation»], loc=«upper left»)
In: plt.show()
In: plot_hist(hist)
Segunda Opción Transferir-Aprendizaje (pesos preentrenados)
-. Lancemos el modelo con pesos de ImageNet previamente entrenados y lo ajustamos en nuestro propio conjunto de datos.
Primer-Paso
-. Transferir el aprendizaje se congelar todas las capas y entrenar solo las capas superiores, la precisión y la pérdida de la validación suelen ser mejores que la precisión y la pérdida del entrenamiento, se debe a que la regularización es fuerte, lo que solo suprime las métricas de tiempo de entrenamiento.
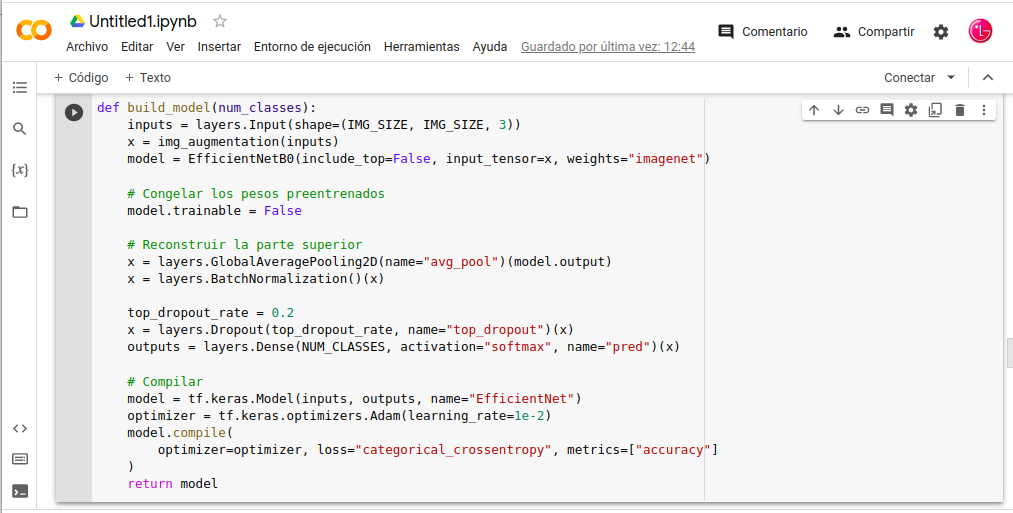
def build_model(num_classes):
- inputs = layers.Input(shape=(IMG_SIZE, IMG_SIZE, 3))
- x = img_augmentation(inputs)
- model = EfficientNetB0(include_top=False, input_tensor=x, weights=«imagenet»)
- model.trainable = False
- x = layers.GlobalAveragePooling2D(name=«avg_pool»)(model.output)
- x = layers.BatchNormalization()(x)
- top_dropout_rate = 0.2
- x = layers.Dropout(top_dropout_rate, name=«top_dropout»)(x)
- outputs = layers.Dense(NUM_CLASSES, activation=«softmax», name=«pred»)(x)
- model = tf.keras.Model(inputs, outputs, name=«EfficientNet»)
- optimizer = tf.keras.optimizers.Adam(learning_rate=1e-2)
- model.compile(
- optimizer=optimizer, loss=«categorical_crossentropy», metrics=[«accuracy»]
- )
- return model
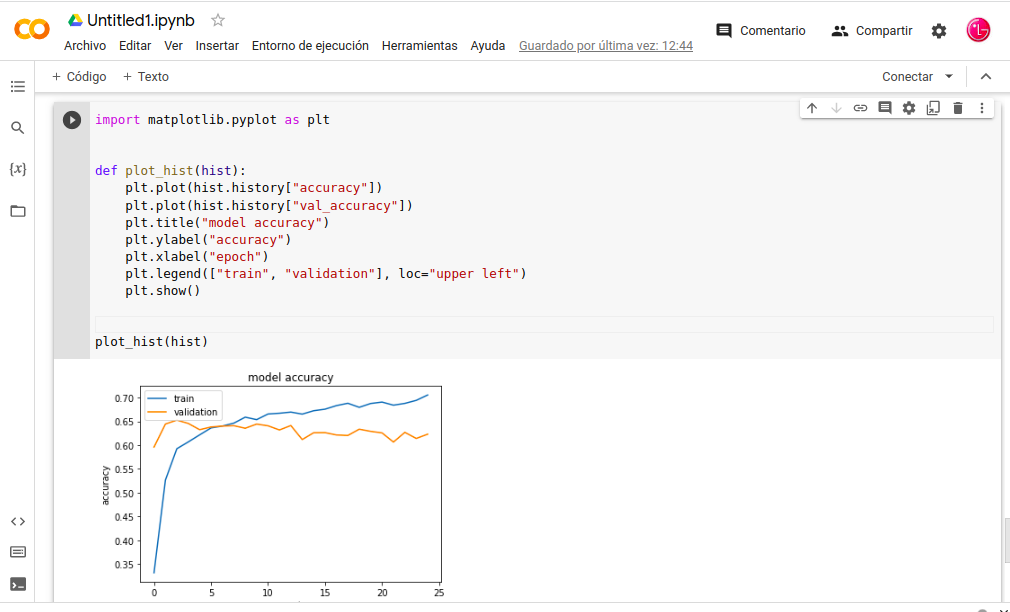
-. Transferir-Aprendizaje se congelar todas las capas y entrenar solo las capas superiores, pasamos tasa de aprendizaje 25epochs con Google-Colaboratory, en la imagen siguiente podemos ver tiempo de procesamiento y configuración.

Segundo-Paso
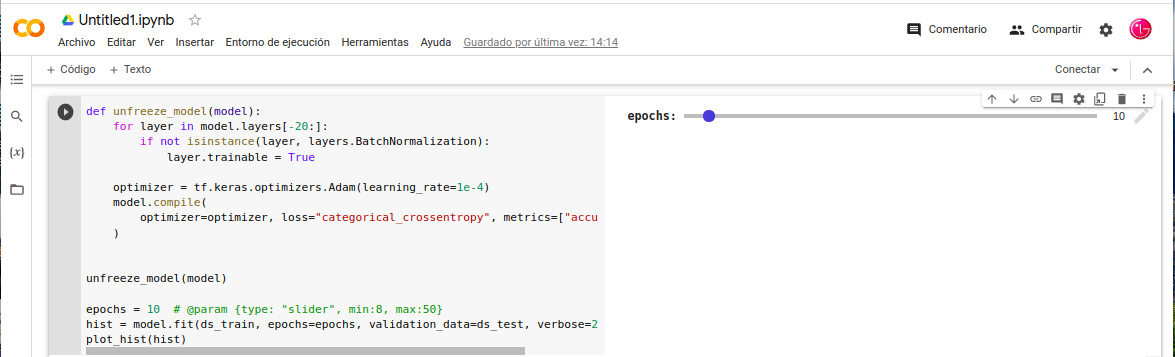
-. Tenemos en este caso, que descongelar todas capas y ajustar el modelo utilizando una tasa de aprendizaje más pequeña. Tenemos que tener en cuenta, cuando necesitamos congelar/descongelar parcialmente un modelo, debemos asegurarnos de que el atributo trainable del modelo esté configurado en True. Descongelamos las 20capas superiores mientras dejamos las capas BatchNormalization congeladas.
- In: def unfreeze_model(model):
- In: for layer in model.layers[-20:]:
- In: if not isinstance(layer, layers.BatchNormalization):
- In: layer.trainable = True
- In: optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
- In: model.compile(
- In: optimizer=optimizer, loss=«categorical_crossentropy», metrics=[«accuracy»]
- In: )
- In: unfreeze_model(model)
- In: epochs = 10 # @param {type: «slider», min:8, max:50}
- In: hist = model.fit(ds_train, epochs=epochs, validation_data=ds_test, verbose=2)
- In: plot_hist(hist)
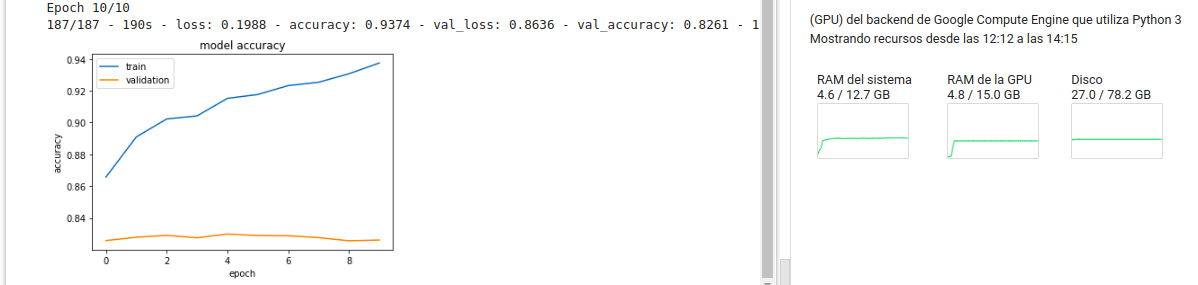
Recapitulando:
Este post lo situó en este lugar, por ser un buen ejemplo de una Aplicación-Keras de una Red-Neuronal un Modelo-Preentrenado basado en un ejemplo que nos facilita el docs-Keras del Modelo-EfficientNet para mas información de la Aplicación-Keras consultar el post “Aplicación-Keras /Keras/Frameworks/Machine-Learning/iA”.
- Referencias: (Entorno-Moreluz)
- Referencias: (Docs-Keras)