

Nota: (En este post se trataremos una red CNN-ConvNet, en la cual veremos todos los Procesos a seguir desde el Dataset a los resultados de salida).
Arquitectura de los Procesos
-. En el siguiente diagrama, tenemos los cuatro procesos básico en la división que he creado, para entender la Topologia de los Procesos a tener en cuenta en las Red-Neuronal-Artificial .
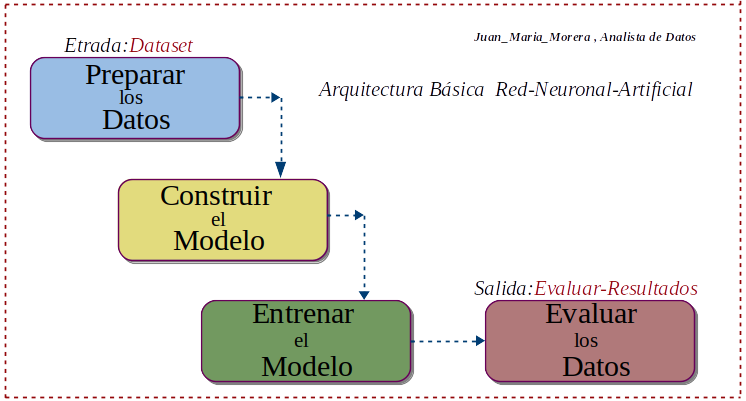
-. Usaremos para el desarrollo de este proyecto: como Framework la API-Keras, Las librerías auxiliares NumPy, Matplotlib, como Dataset el conjunto Mnist y como herramienta de trabajo Google-Colaboratory para escribir y ejecutar código en la nube de Google.
Preparación-Dataset
- Lo primero cargamos las librerías necesarias, “numpy” , “ tensorflow” , “ keras” , “matplotlib”.
- Mnist es una Base-Datos de dígitos escritos a mano tiene dos conjunto de datos: de Entrenamiento y Prueba y se carga este conjunto de datos Mnist con función .load_data.
- Keras usa un Array-Multidimensional de NumPy como estructura de datos.
Cargamos Librerias:
- In: import numpy as np
- In: import tensorflow as tf
- In: from tensorflow import keras
- In: import matplotlib.pyplot as plt
- In: from keras import layers

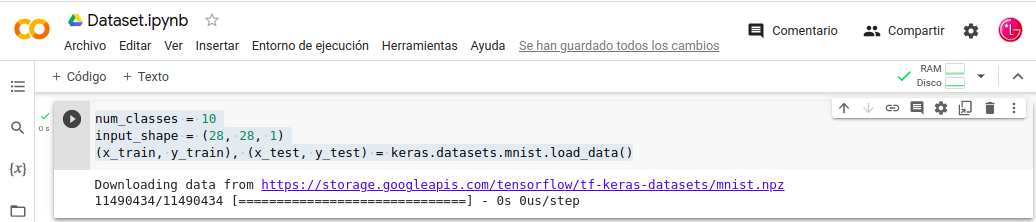
-. Damos parámetros a los datos de entrada, cargamos los datos los dividimos entre Entrenamiento “train” y Prueba “test”. Aquí es donde usamos un Array-Multidimensional de NumPy como estructura de datos.
- In: num_classes = 10
- In: input_shape = (28, 28, 1)
- In: (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
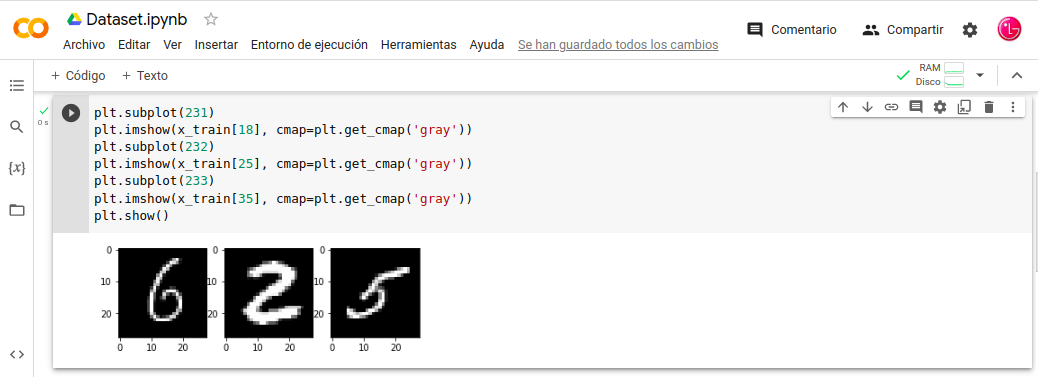
Nota: Podemos visualizar el conjunto de datos-mnist; por supuesto después de descargar datasets.mnist y usado como estructura de datos el Array-Multidimensional de NumPy, para ello utilizaremos la librería auxiliar Matplotlib podemos cargar tres imágenes a modo de ejemplo.
Visualización del conjunto de datos mnist:
- In: plt.subplot(231)
- In: plt.imshow(x_train[18], cmap=plt.get_cmap(‘gray’))
- In: plt.subplot(232)
- In: plt.imshow(x_train[25], cmap=plt.get_cmap(‘gray’))
- In: plt.subplot(233)
- In: plt.imshow(x_train[35], cmap=plt.get_cmap(‘gray’))
- In: plt.show()
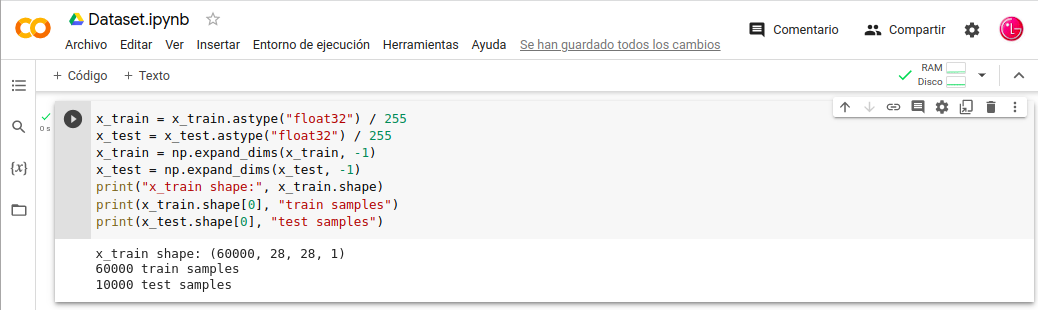
-. Escalamos la imagen y aseguramos que la imagen tenga el formato que nos interesa 28,28,1 una imagen que tenga un tamaño de 28x28 y en blanco/negro.
- In: x_train = x_train.astype(«float32») / 255
- In: x_test = x_test.astype(«float32») / 255
- In: x_train = np.expand_dims(x_train, -1)
- In: x_test = np.expand_dims(x_test, -1)
- In: print(«x_train shape:», x_train.shape)
- In: print(x_train.shape[0], «train samples»)
- In: print(x_test.shape[0], «test samples»)
. Por ultimo convertiremos los “vectores.clase” a “matrices-binarias.
- In: y_train = keras.utils.to_categorical(y_train, num_classes)
- In: y_test = keras.utils.to_categorical(y_test, num_classes)

Nota: con esto hemos terminado el Preprocesamiento de la Base-Datos de dígitos a mano de Minst, tenemos que recordar que Redes-Neuronales-Artificiales “Modelo” no procesan datos sin procesar previamente, ni archivos “Texto”.”Imágenes”,”CSV” etc. realmente procesan representaciones vectorizadas y estandarizadas. Tenemos que preparan los datos antes de entrenar un modelo, transformándolos en matrices y objetos (NumPy).
Construir el Modelo
-. Pasamos a generar el modelo que deseamos: En este caso un Modelo-Secuencial; Se crea una instancia un objeto del tipo Model y continuación a este Model, se le van añadiendo las capas que conforman la arquitectura una detrás de la otra.
-. El Modelo-Sequential es una pila de capas donde cada capa tiene exactamente un tensor de entrada y un tensor de salida.
Generamos el Modelo-Secuencial:
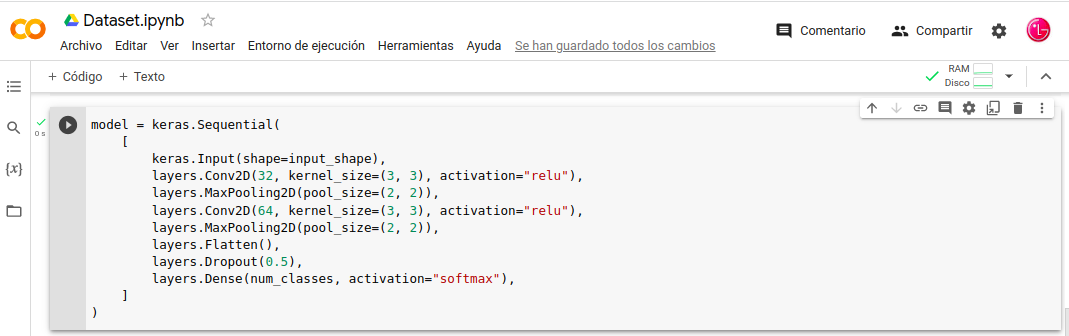
- In: model = keras.Sequential(
- In: [
- In: keras.Input(shape=input_shape),
- In: layers.Conv2D(32, kernel_size=(3, 3), activation=«relu»),
- In: layers.MaxPooling2D(pool_size=(2, 2)),
- In: layers.Conv2D(64, kernel_size=(3, 3), activation=«relu»),
- In: layers.MaxPooling2D(pool_size=(2, 2)),
- In: layers.Flatten(),
- In: layers.Dropout(0.5),
- In: layers.Dense(num_classes, activation=«softmax»),
- In: ]
- In: )
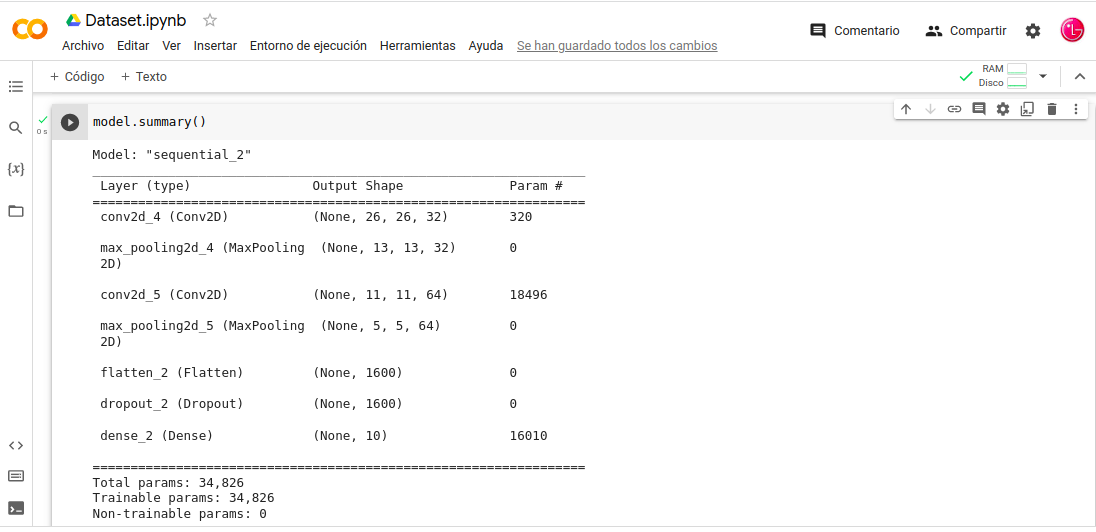
Nota: veremos el resumen del de este Modelo sus capas conv2d con sus capas de pooling2d correspondiente y atraves de model.layers el listado de todas las layers mas detallado.
Resumen del Modelo:
- In: model.summary()
Esta capas son accesibles a través .layers:
- In: model.layers
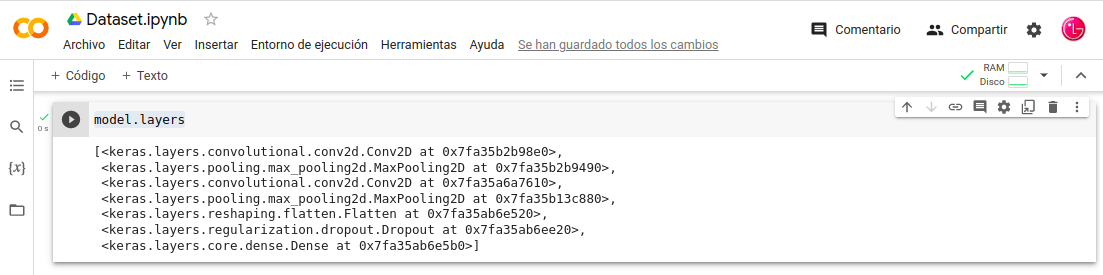
Aclaremos las ultimas tres Layers del Modelo:
- layers.Flatten(), aplana la entrada, no afecta el tamaño del lote.
- layers.Dropout(0.5), La layers-Dropout establece aleatoriamente las unidades de entrada en 0 con una frecuencia de rate en cada paso durante el tiempo de entrenamiento, lo que ayuda a evitar el sobreajuste.
- layers.Dense(num_classes, activation=»softmax») Las activaciones se pueden usar a través de una Activation-capa o a través del activation-argumento admitido por todas las layers delanteras.
Entrenar el Modelo
El entrenamiento del Modelo lo haremos por matrices Numpy con .fit() :
- In: batch_size = 128
- In: epochs = 15
- In: model.compile(loss=«categorical_crossentropy», optimizer=«adam», metrics=[«accuracy»])
- In: model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
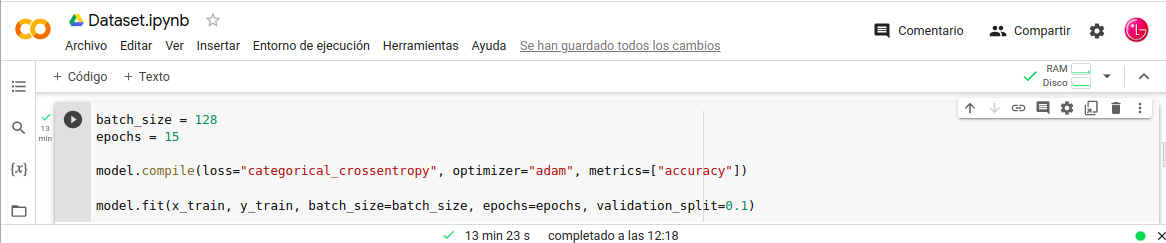

Nota: Nuestro Google-Colaboratory le a costado 13min 23s ejecutar el entrenamiento y a continuación unas aclaraciones sobre el entrenamiento que acabamos de realizar.
batch_size =
- El batch_size es el número de muestras de prueba; disponemos de un conjunto de prueba de 1000 imágenes configurar un valor batch_size igual a 100. El algoritmo toma las primeras 100 muestras (del 1 al 100) del conjunto de datos de entrenamiento y entrena la red. Luego, toma las segundas 100 muestras (del 101 al 200) y vuelve a entrenar la red, hasta terminar con todo el conjunto de prueba.
epochs =
- Las Épocas tienen un corte “tamaño” arbitrario; el número de épocas significa cuántas veces pasas por tu conjunto de entrenamiento. El modelo se actualiza cada vez que se procesa un lote, lo que significa que se puede actualizar varias veces durante una época. Si batch_size se establece igual a la longitud de x, el modelo se actualizará una vez por época.
model.compile()
- Realmente la Compilación es el paso final en la creación de un Modelo. Una vez realizada la Compilación, podemos pasar a la fase de Entrenamiento. algunos conceptos necesarios para el proceso de compilación. “Loss” – “Optimizador” – “Métrica”.
- Optimizador: Hay varios optimizadores como, «adam» , «SGD«
- Loss: Pasamos una función de pérdida para el modelo «categorical_crossentropy»,
- Metrics: Pasaremos la métrica sobre la que queremos que se puntue el modelo «accuracy»
model.fit()
- Los Modelos son entrenados por matrices NumPy usando fit() , entrena el modelo para un número fijo de épocas . esta función de ajuste se usa para evaluar su modelo en el entrenamiento, se puede utilizar para representar gráficamente el rendimiento del modelo. model.fit(X, y, epochs = , batch_size = )
Evaluar el Modelo-Entrenado
-. Tenemos el Modelo Entrenado y ahora queremos Evaluar este Modelo-Secuencial para ello usaremos model.evaluate() y nos dará los resultado de pérdida y la precisión.
- In: score = model.evaluate(x_test, y_test, verbose=0)
- In: print(«Test loss:», score[0])
- In: print(«Test accuracy:», score[1])

Recopilando:
En esta Red- Neuronal-Artificial del tipo ConvNet CNN, se han seguido todos los procesos desde la preparación del Dataset de entrenamiento posteriormente lanzamos el constructor del Modelo-Secuencial seguimos entrenando el Modelo y por ultimo evaluamos el Modelo que acabamos de entrenar.
- Referencias: (Entorno-Moreluz)
- Referencias: (Docs-Keras)