

Nota: (La Artificial-Neuronal-Network (ANN) & Redes-Neuronales-Artificiales (RNA), son redes de neuronas artificiales . Son objeto de investigación en neuroinformática y representan una rama de la inteligencia artificial) .
ANN & RNA
-. Al igual que las neuronas-artificiales, las redes-neuronales-artificiales tienen un modelo biológico. Se comparan con las redes neuronales naturales , que representan una red de neuronas en el sistema nervioso de un ser vivo. Las ANN se tratan más de una abstracción de dicho modelo del procesamiento de información y menos de emular redes neuronales y neuronas biológicas, que es más un tema de neurociencia-computacional . Se puede observar que los límites entre estas subdisciplinas están desapareciendo cada vez más, lo que se puede atribuir al carácter todavía muy dinámico e interdisciplinario de esta rama de investigación.
-. Las redes neuronales son una de las familias de algoritmos de ML. Se trata de una técnica que se inspira en el funcionamiento de las neuronas de nuestro cerebro. Se basan: dados unos parámetros hay una forma de combinarlos para predecir un cierto resultado. Por ejemplo, sabiendo los píxeles de una imagen habrá una forma de saber qué número hay escrito. Los datos de entrada van pasando secuencialmente por distintas » capas» en las que se aplican una serie de reglas de aprendizaje moduladas por una función peso. Tras pasar por la última capa, los resultados se comparan con el resultado «correcto«, y se van ajustando los parámetros (dados por las funciones «peso«).
-. Aunque los algoritmos y en general el proceso de aprendizaje son complejos, una vez la red ha aprendido, puede congelar sus pesos y funcionar en modo recuerdo o ejecución. Google usa este tipo de algoritmos, por ejemplo, para las búsquedas por imagen.
-. Las redes neuronales artificiales (también conocidas como sistemas conexionistas).Es un modelo computacional que Consiste en un conjunto de unidades, llamadas neuronas artificiales, conectadas entre sí para transmitirse señales. La información de entrada atraviesa la red neuronal (donde se somete a diversas operaciones) produciendo unos valores de salida.
-. Estos sistemas aprenden y se forman a sí mismos, en lugar de ser programados de forma explícita, y sobresalen en áreas donde la detección de soluciones o características es difícil de expresar con la programación convencional. Para realizar este aprendizaje automático, normalmente, se intenta minimizar una función de pérdida que evalúa la red en su total. Los valores de los pesos de las neuronas se van actualizando buscando reducir el valor de la función de pérdida. Este proceso se realiza mediante la propagación hacia atrás.
-. El objetivo de la red neuronal es resolver los problemas de la misma manera que el cerebro humano, aunque las redes neuronales son más abstractas. Las redes neuronales actuales suelen contener desde unos miles a unos pocos millones de unidades neuronales.
-. Nuevas investigaciones sobre el cerebro a menudo estimulan la creación de nuevos patrones en las redes neuronales. Un nuevo enfoque está utilizando conexiones que se extienden mucho más allá y capas de procesamiento de enlace en lugar de estar siempre localizado en las neuronas adyacentes. Otra investigación está estudiando los diferentes tipos de señal en el tiempo que los axones se propagan, como el aprendizaje profundo, interpola una mayor complejidad que un conjunto de variables booleanas que son simplemente encendido o apagado.
Fuentes para para aprender mas:
- https://es.wikipedia.org/wiki/Conexionismo
- https://es.wikipedia.org/wiki/Modelo_computacional
- https://es.wikipedia.org/wiki/Neurona_de_McCulloch-Pitts
- https://es.wikipedia.org/wiki/Función_de_activación
- https://es.wikipedia.org/wiki/Aprendizaje_automático
- https://es.wikipedia.org/wiki/Función_de_pérdida
- https://es.wikipedia.org/wiki/Propagación_hacia_atrás
- https://es.wikipedia.org/wiki/Aprendizaje_profundo
- https://es.wikipedia.org/wiki/Tipo_de_dato_lógico
- https://es.wikipedia.org/wiki/Visión_artificial
- https://es.wikipedia.org/wiki/Reconocimiento_del_habla
- https://es.wikipedia.org/wiki/Sistema_experto
- https://es.wikipedia.org/wiki/Programación_estructurada
- https://es.wikipedia.org/wiki/Sistema_dinámico
Deep Learning o Aprendizaje Profundo
-. No existe una definición única de lo que es Deep Learning. En general, cuando hablamos de Deep Learning, nos referimos a una clase de algoritmos de Machine Learning basados en redes neuronales que, como hemos visto, se caracterizan por un procesamiento de los datos en cascada. La señal de entrada se va propagando por las distintas capas, y en cada una de ellas se somete a una transformación no lineal que va extrayendo y transformando las variables según determinados parámetros (pesos o umbrales). No hay un límite establecido para el número de capas que debe tener una red neuronal para considerarse Deep Learning. Sin embargo, se considera que el aprendizaje profundo surgió en los años 80, a partir de un modelo neuronal de entre 5 o 6 capas, el neocognitrón, creado por el investigador japonés Kunihiki Fukushima. Las redes neuronales son muy efectivas en la identificación de patrones.
-. Aprendizaje Profundo-Deep Learning : Es una evolución de las Redes Neuronales Artificiales (RNA),(ANN) ,que aprovechan el abaratamiento de la tecnología y la mayor capacidad de ejecución, memoria y disco para explotar gran cantidad de datos en enormes redes neuronales interconectarlas en diversas capas que pueden ejecutar en paralelo para realizar cálculos.
-. Un ejemplo muy llamativo de aplicación de Deep Learning es el proyecto conjunto de Google con las Universidades de Stanford y Massachusetts para mejorar las técnicas de procesamiento de lenguaje natural de un tipo de IA llamada Modelo de Lenguaje de Redes Neuronales Recurrentes ( Recurrent Neural Network Language Model RNNLM). Se usa para traducción automática y creación de subtítulos, entre otras cosas. Básicamente, va construyendo frases palabra a palabra, basándose en la palabra anterior. Incluso, puede llegar a escribir poemas.
La Neural Network
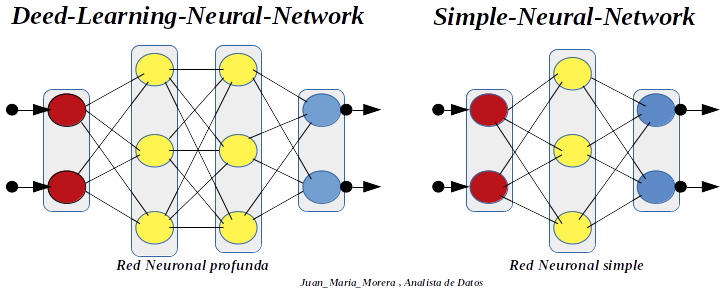
-. Las ramificaciones de salida de algunas neuronas son las ramificaciones de entrada de otras, y así sucesivamente. Pero vemos un par de diferencias entre las capas. Las neuronas de color rojo no tienen ramificaciones de entrada. Son información que vamos a dar a las neuronas «desde el exterior», o «estímulo inicial». Las neuronas de color azul tiene ramificaciones de salida que no están conectadas a otras neuronas. Son la información de salida de la red neuronal o «estímulo final». Dependiendo del número de capas ocultas (amarillas) podemos hablar de una red neuronal simple o profunda.
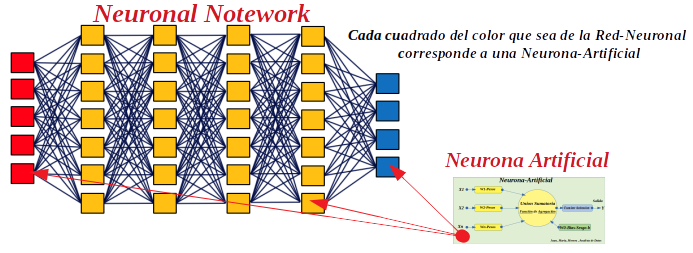
Nota: Las redes-neuronales-artificiales sirven como aproximadores de funciones universales. Los valores se propagan desde la capa de entrada a la de salida, con una función de activación que se ocupa de la no linealidad. Al entrenar, se determina un error; Con la ayuda de la retroalimentación de errores y un proceso de optimización, los pesos se ajustan capa por capa.
Procesado de la información
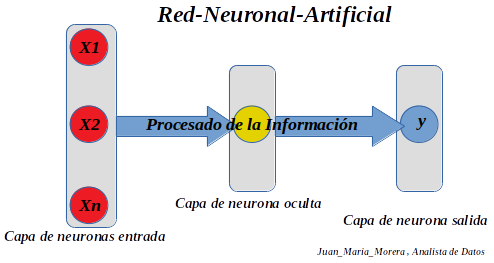
Red-Neuronal-Artificial
-. Tendemos una capa de neuronas de entrada, una capa de neuronas ocultas y una capa de neuronas de salida .Todas las variables independientes de la capa de entrada, pertenecen a una única observación, una única muestra, «un sólo registro de la base de datos».
-. En el núcleo de la neurona es donde se procesan las señales de entrada y los pesos. Una de las formas es multiplicar cada señal de entrada por su peso y sumarlo todo, es decir, hacer una combinación lineal de los pesos de las conexiones y las entradas.
-. Valores de salida y pesos de las redes neuronales: Cada una de estas neuronas artificiales tiene una o más entradas, y a su vez cada una de dicha entradas es estimulada por los datos del proceso o por la salida de una de las neuronas de una capa anterior y están asociadas a un peso sináptico, el cual regula la intensidad de la señal de entrada. Dicha regulación del peso sináptico es ajustada en la etapa de aprendizaje. A todas estas señales reguladas de estas entradas se les realiza una sumatoria, suma a la cual se resta un valor inhibidor que también es regulable en la etapa de aprendizaje, y es conocido como bias. Todo el conjunto anteriormente descrito también se le conoce como suma ponderada, y es el tipo más común de función de propagación. El resultado de esta función de propagación alimenta su vez a una función no lineal, cuya salida se conecta a la o las neuronas artificiales de la siguiente capa, y es conocida como función de activación .
Tipos de funciones de activación
Funciones de activación no lineales:
-. Estas funciones se utilizan para separar los datos que no se pueden separar linealmente y son las funciones de activación más utilizadas. Una ecuación no lineal gobierna el mapeo de entradas a salidas.
-. Existen diferentes funciones de activación que cumplen este objetivo, la más habitual son :
- Función escalón (threshold) . Paso unitario ( Umbral )
- Función (Sigmoide , Sigmoide) conocida como (Logica)
- Función (Tanh), (Tangente Hiperbolica)
- Funcion (ReLU) , ( Funcion Rectificadora )
- Funcion (ReLU ) , ( ReLU con fugas )
- Funcion (ReLU paramétrico)
- Funcion ( SWISH ) , ( SILBIDO ) ( función de activación autónoma )
-. Primero se calcula la combinación lineal de los pesos y las entradas.
-. Las funciones de activación no son más que la manera de trasmitir esta información por las conexiones de salida.
-. En general, las funciones de activación se utilizan para dar una «no linealidad» al modelo y que la red sea capaz de resolver problemas más complejos. Si todas las funciones de activación fueran lineales, la red resultante sería equivalente a una red sin capas ocultas.
-. En redes computacionales, la Función de Activación de un nodo define la salida de un nodo dada una entrada o un conjunto de entradas. Se podría decir que un circuito estándar de computador se comporta como una red digital de funciones de activación al activarse como «ON» (1) u «OFF» (0), dependiendo de la entrada . Esto es similar al funcionamiento de un Perceptró en una Red neuronal artificial.
Configuración de la red neuronal
-. Ya tenemos los ingrediente básicos para configurar una red neuronal. Una capa de neuronas de entrada, donde pasaremos información a la red a modo de estímulos, una capa de neuronas oculta, que se encargará del procesado de la información proporcionada por la capa de entrada, y una capa de salida que procesará la información proporcionada por la capa oculta para obtener el resultado final de la red neuronal para una entrada específica.
Configuración de la red neuronal
-. Ya tenemos los ingrediente básicos para configurar una red neuronal. Una capa de neuronas de entrada, donde pasaremos información a la red a modo de estímulos, una capa de neuronas oculta, que se encargará del procesado de la información proporcionada por la capa de entrada, y una capa de salida que procesará la información proporcionada por la capa oculta para obtener el resultado final de la red neuronal para una entrada específica.
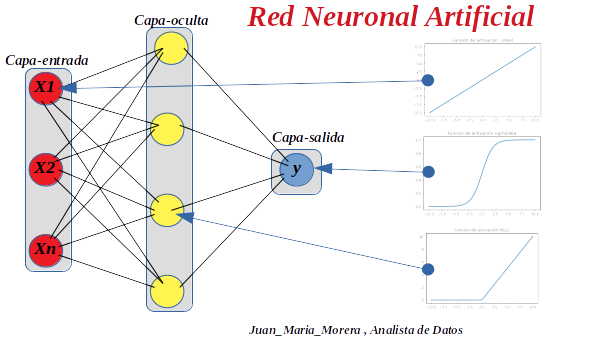
-. Decir que la ponderación de las señales de salida la hemos hecho con una combinación lineal en la capa de entrada, en la capa oculta usamos una función rectificadora y en la de salida usamos una función sigmodea. Sepuede usar en cualquier redes neuronales otro tipo de función que mejor se ajuste al problema que hay que resolver, esto es sólo un ejemplo.
-. La elección un una función de activación u otra dependerá de varios factores . Uno de ellos es el rango de valores que queremos en la salida de la neurona. Si no hay restricciones en el rango, utilizaremos la función identidad que propagará en la salida el valor de entrada. Si la restricción es únicamente que el valor de salida debe ser positivo, sin límite de cantidad, elegiremos una función rectificadora. Quizás nos interese una salida binaria 1 y 0 para clasificar, por lo que elegimos, por ejemplo, la función escalón. Puede que usemos un algoritmo de aprendizaje que hace uso de derivadas. Entonces utilizaremos funciones de activación donde la derivada esté definida en todo el intervalo. Por ejemplo la sigmoidal o la tangente hiperbólica, teniendo en cuenta que son más costosas en términos computacionales .
La función de costes
-. Durante el entrenamiento, tenemos los valores de entrada y sabemos cuáles son sus respectivas salidas . Lo que queremos es ajustar los pesos para que la red neuronal aprenda, y que los valores de salida de la red se acerquen lo más posible a los valores reales conocidos .
-. La función de coste es una función que mide, en cierto modo, la «diferencia» entre el valor de salida y el valor actual. En este ejemplo usaremos el error cuadrático medio. Por supuesto, puede ser una función más compleja.
-. Alimentamos en diferentes iteraciones a la red neuronal con los mismos datos de entrenamiento que tenemos, y en cada iteración intentamos minimizar la función de coste. Es decir que la diferencia entre los valores de salida y los reales sean cada vez menores . Como los datos de entrada son los que son, sólo podemos conseguir esto ajustando los pesos de las conexiones entre neuronas al final de cada iteración .
-. Una vez finalizado el proceso, tendremos una red neuronal entrenada lista para predecir . En general la red hará predicciones excelentes para datos que hemos usado para entrenarla. Pero para evaluar la calidad de predicción de la red neuronal es necesario usar datos que no hayan sido usados para optimizar los pesos de las conexiones de la red .
Asignación de pesos en Redes Neuronales
-. Una de las partes más importantes de las redes neuronales es la asignación de los pesos para cada conexión neuronal. Entre los algoritmos más usados para asignar estos pesos se encuentra el llamado back propagation (propagación hacia atrás).
-. Una vez que tenemos el diseño de nuestra red neuronal, necesitamos asignar pesos a cada conexión neuronal, de manera que la salida de la función de activación de cada neurona se vea afectada por el paso de cada conexión. Existen varios algoritmos de asignación de pesos , como el descenso del gradiente o el back propagation. Veremos en detalle este último, pero primero. Echemos un vistazo a un problema general que tenemos al asignar los pesos, clave para entender la existencia de estos algoritmos.
Problema general de la asignación de Pesos
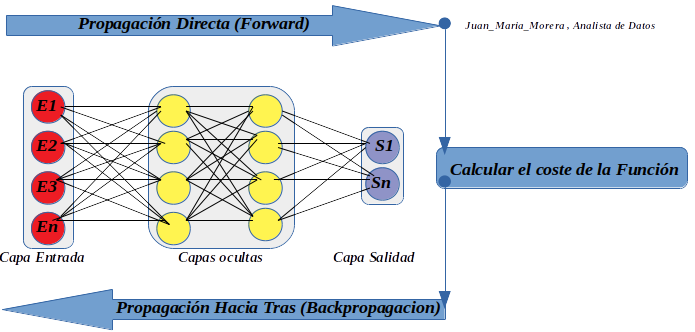
-. Sabemos que la información se introduce en la primera capa de neuronas por la izquierda, propagándose hacia delante atravesando las diferentes capas ocultas, hasta que llega a la capa de neuronas de salida, dando el resultado final. Este resultado se compara con los valores reales para calcular el error que se comete, y propagar este error hacia atrás a través de la red neuronal, lo que nos va a permitir ajustar los pesos durante el proceso de entrenamiento. pero es muy importante recalcar que en la propagación hacia atrás todos los pesos se ajustan de manera simultánea.
-. Pero, ¿por qué complicarnos la vida con algoritmos de ajuste de pesos aparentemente tan difíciles, pudiendo asignar los pesos y probar con todas las combinaciones posibles para al final quedarnos con la que minimice el error? Esto es lo que se denomina ajuste de pesos por fuerza bruta. Como esto no es viable, incluso teniendo una red neuronal muy simple .(no tenemos la potencia computacional necesaria) .
Back-Propagation
Nota: Algoritmo back-propagation pasos necesarios para implementar este algoritmo.
- Asignamos a cada conexión neuronal un peso con un valor pequeño, pero no nulo.
- Introducimos la primera observación de nuestro conjunto de entrenamiento por la capa inicial de la red neuronal.
- La información se propaga de izquierda a derecha, activando cada neurona que ahora es afectada por el peso de cada conexión, hasta llegar a la capa de neuronas de salida, obteniendo el resultado final para esa observación en concreto.
- Medimos el error que hemos cometido para esa observación.
- Comienza la propagación hacia atrás de derecha a izquierda, actualizando los pesos de cada conexión neuronal, dependiendo de la responsabilidad del peso actualizado en el error cometido.
- Repetimos los pasos desde el paso 2, actualizando todos los pesos para cada observación o conjunto de observaciones de nuestro conjunto de entrenamiento.
- Cuando todas las observaciones del conjunto de entrenamiento ha pasado por la red neuronal, hemos completado lo que se denomina un Epoch. Podemos realizar tantos Epochs como creamos convenientes.
Recapitulando:
Los conceptos de Redes Neuronales, evolucionan tan rápidamente en el procesado de la información que cuando se publique este post estará obsoleto, en el examinamos los tipos de funciones de activación, sus configuraciones y los conceptos de (Pesos),(backpropagacion),etc.
- Referencias: Entorno-Moreluz
- Referencias: Para-saber-mas