

Nota: (Datos-Dataset hace referencia a una única base de datos de origen, la cual se puede relacionar con otras, cada columna del Dataset representa una variable y cada fila corresponde a cualquier dato que estemos tratando).
Procesado de los Datos:
-. Dataset son datos habitualmente tabulada; es conjunto de datos contiene los valores para cada una de las variables organizadas como columnas, como por ejemplo la volumen y el peso de un objeto, que corresponden a cada miembro del conjunto de datos, que están organizados en filas. Cada uno de estos valores se conoce con el nombre de dato. Los datos también puede consistir en una colección de documentos o de archivos. Estos datos pude ser tan grandes que no se pueden procesar con procedimientos tradicionales esto lo llamamos Big-Data.
-. Empecemos con los Datos-Dataset; la Red-Neuronal-Artificial no procesan datos sin procesar previamente, ni archivos “Texto”.”Imágenes”,”CSV” etc. realmente procesan representaciones vectorizadas y estandarizadas. tf.data.Dataset admite la escritura de canalizaciones de entrada descriptivas y eficientes, preparan los datos antes de entrenar un modelo, transformándolos en matrices y objetos (NumPy).
Carguemos los Datos-Dataset:
-. Disponemos de tres clases en los modelos de Keras.
- NumPy arrays bibliotecas basadas en Python como Scikit-Learn esta opción es recomendables siempre y cuando coja en la memoria.
- tf.data.Dataset Este objetos de TensorFlow ofrece un alto rendimiento, más adecuada para conjuntos de datos que no caben en la memoria y que se transmiten desde el disco o desde un sistema de archivos distribuido.
- Generadores de Python que producen lotes de datos.
-. Para entrenar un modelo tendremos que tener los datos en uno de estos formatos. Kera dispone utilidades para convertir los datos sin procesar en la ISO disco en Dataset ya procesado y listo para usar.
-. Usaremos los datos MNIST (Reconocimiento de digitos), los datos es habitual dividirlos en tres conjuntos:
- Datos de entrenamiento: training-train son los que se usan para que el algoritmo de aprendizaje obtenga los parámetros del modelo.
- Datos de validación: validation los datos de validación han influido en el modelo para que se ajustara también a los datos de validación
- Datos de prueba: test la evaluación final del modelo que solo se usarán al final de todo el proceso.
Nota: La base de Dataset-Mnist este es el enlace.
Array multidimensional de Numpy
-. La primera NumPy bibliotecas nos vale para Keras y Scikit-Learn esta opción es recomendables siempre y cuando coja en la memoria.
Nota: una tupla no puede ser modificada,no se pueden añadir ni eliminar elementos .
Tupla de arreglos NumPy : (x_train, y_train), (x_test, y_test).
- x_train : matriz uint8 NumPy de datos de imagen en escala de grises con formas (60000, 28, 28), que contiene los datos de entrenamiento. Los valores de píxeles oscilan entre 0 y 255.
- y_train : uint8 NumPy matriz de etiquetas de dígitos (enteros en el rango 0-9) con forma (60000,)para los datos de entrenamiento.
- x_test : matriz uint8 NumPy de datos de imagen en escala de grises con formas (10000, 28, 28), que contiene los datos de prueba. Los valores de píxeles oscilan entre 0 y 255.
- y_test : uint8 NumPy matriz de etiquetas de dígitos (enteros en el rango 0-9) con forma (10000,)para los datos de prueba.
Nota: Keras usa un array multidimensional de Numpy como estructura de datos.
Cragamos Librerias:
- In: import numpy as np
- In: import tensorflow as tf
- In: from tensorflow import keras
- In: import matplotlib.pyplot as plt
Importamos Mnist creamos array multidimensional de Numpy:
- from keras.datasets import mnist
- (x_train, y_train), (x_test, y_test) = mnist.load_data()
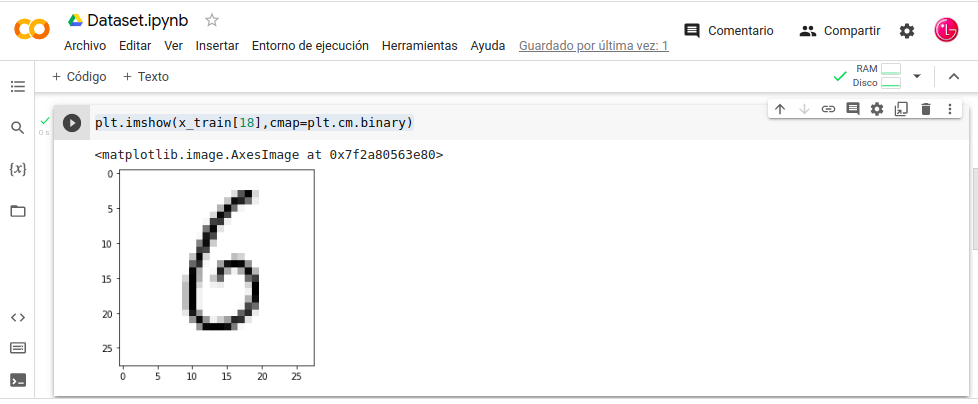
Visualizar lo cargado cambiar-Nº:
- In: plt.imshow(x_train[18],cmap=plt.cm.binary)
Recopilando:
Una cuestión Importante, es el proceso como cargamos los datos, sean los de entrenamiento o los datos de procesamiento cuando tengamos todo listo para pasar a producción, en esta ocasión usaremos Keras y las librerías de apoyo NumPy y matplotlib.
- Referencias: (Entorno-Moreluz)
- Referencias: (Docs-Keras)