

Descarga Spark:(descomprimir el fichero.tgz)-(crear)Mover a la carpeta /spark
https://spark.apache.org/downloads.html
- In: root@juan-Aspire-ES1-512:/# curl -O https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
- In: root@juan-Aspire-ES1-512:/# tar xvf spark-3.1.1-bin-hadoop3.2.tgz
- In: root@juan-Aspire-ES1-512:/# mv spark-3.1.1-bin-hadoop3.2/ /spark
Descarga de datos TXT y CSV :
Descargamos dos ficheros con datos para trabajar con BigData , uno con el libro ‘Moby Dick’ y el otro con unos datos de costes por trabajador del ayuntamiento de Chicago(En formato CSV). Dos ejemplos que se encuentra el la literatura de estos temas, podría usar los del ayuntamiento de Madrid los cuales no son tan sencillos de encontrar como los de Chicago.
- In: root@juan-Aspire-ES1-512:/spark# wget -O data.csv https://data.cityofchicago.org/api/views/xzkq-xp2w/rows.csv?accessType=DOWNLOAD
- In: root@juan-Aspire-ES1-512:/spark# curl -O https://www.gutenberg.org/cache/epub/2489/pg2489.txt
- In: root@juan-Aspire-ES1-512:/spark/sbin# ls
Arrancamos el cluster:
Apache Spark utiliza una arquitectura Master/Esclavo, por lo tanto lo primero será arrancar el nodo máster.Una vez tenemos arrancado el nodo máster, este nos arranca una consola web donde podremos consultar el estado del cluster y la URL donde se tendrán que conectar el resto de nodos esclavos .
Arrancamos el Master :
- In: root@juan-Aspire-ES1-512:/spark# ./sbin/start-master.sh
- Out: starting org.apache.spark.deploy.master.Master, logging to /spark/logs/spark-root org.apache.spark.deploy.master.Master-1-juan-Aspire-ES1-512.out
Detenemos el Master :
- In: root@juan-Aspire-ES1-512:/spark# ./sbin/stop-master.sh
- Out: stopping org.apache.spark.deploy.master.Master
Arrancamos la consola wed http://127.0.0.1:8080/
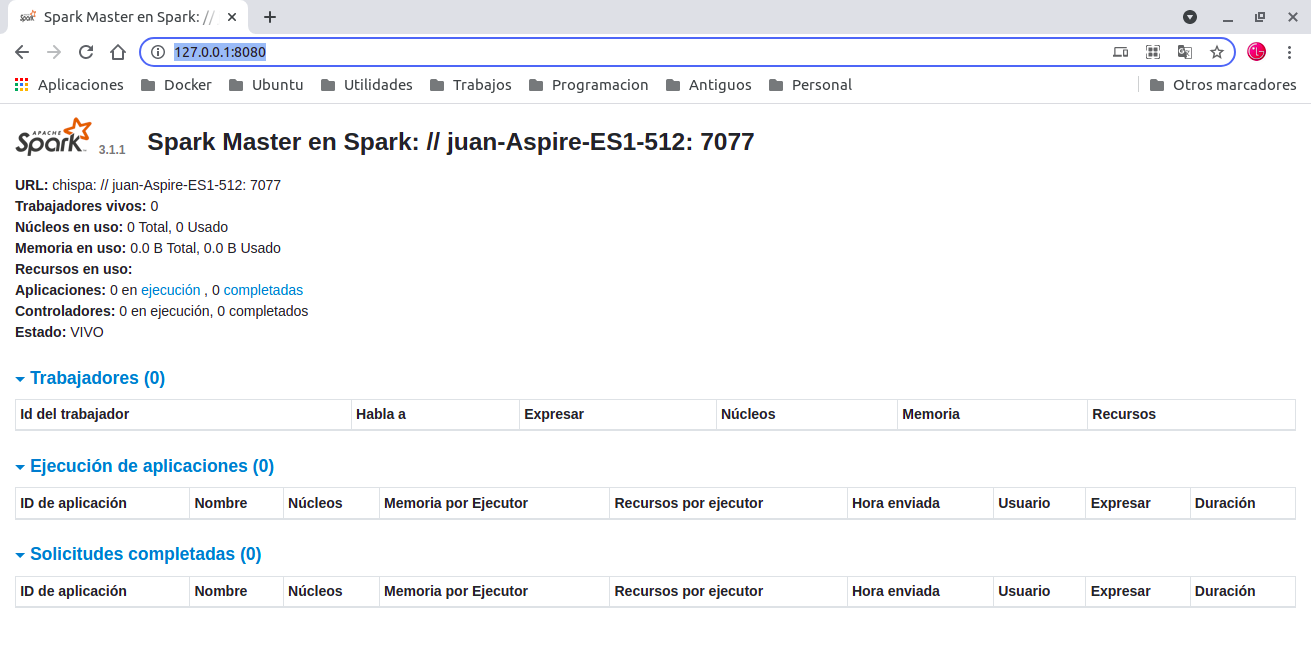
URL: spark://juan-Aspire-ES1-512:7077
- In: root@juan-Aspire-ES1-512:/spark# ./sbin/start-slave.sh spark://juan-Aspire-ES1-512:7077
- Out: This script is deprecated, use start-worker.sh starting org.apache.spark.deploy.worker.Worker, logging to /spark/logs/spark-root org.apache.spark.deploy.worker.Worker-1-juan-Aspire-ES1-512.out
Recopilando :
En este laboratorio esta realizado con fines didáctico, no es conveniente instalar directamente en un ordenado personal sino como mínimo en el venv o en un contenedor-Docker. Descarga de datos TXT y CSV para ver como es procedimiento . En prosimos laboratorios iremos escalados. Origen de este laboratorio (Entorno-Moreluz)