

Nota: A continuación escalamos al utilizar Dockerfile, utilizamos la imagen base (ubuntu-python-pip:latesh) que es la creada en el posts anterior.
Creamos el fichero dockerfile dentro de la carpeta my-dockerfile en la que creamos una nueva carpeta
Creamos una carpeta dentro de my-dockerfile :
- In: root@juan-Aspire-ES1-512:/my-dockerfile# mkdir base-spark-hadoop
Creamos un archivo dockerfile con nano :
- In: root@juan-Aspire-ES1-512:/my-dockerfile/base-spark-hadoop# nano dockerfile
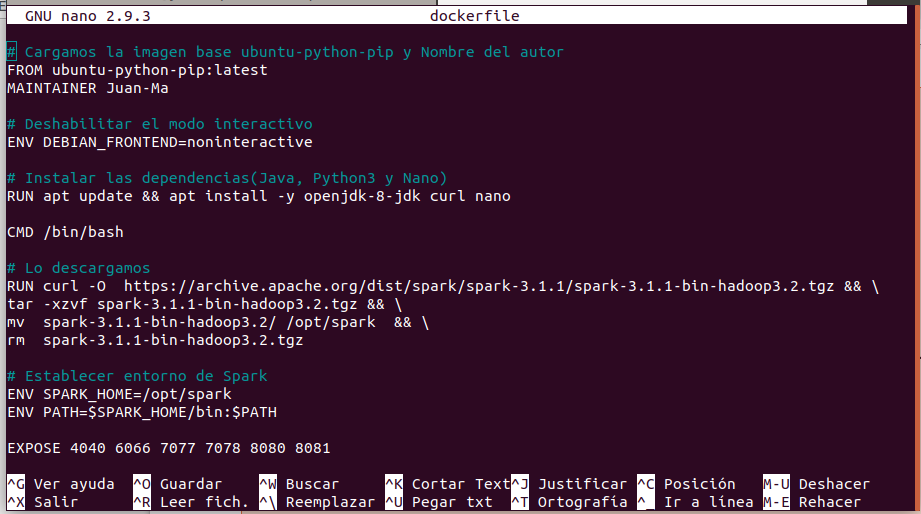
# Cargamos la imagen base ubuntu-python-pip y Nombre del autor
- FROM ubuntu-python-pip:latest
- MAINTAINER Juan-Ma
# Deshabilitar el modo interactivo
- ENV DEBIAN_FRONTEND=noninteractive
# Instalar las dependencias(Java, Python3 y Nano)
- RUN apt update && apt install -y openjdk-8-jdk curl nano
- CMD /bin/bash
# Lo descargamos
- RUN curl -O https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz && \
- tar -xzvf spark-3.1.1-bin-hadoop3.2.tgz && \
- mv spark-3.1.1-bin-hadoop3.2/ /opt/spark && \
- rm spark-3.1.1-bin-hadoop3.2.tgz
# Establecer entorno de Spark
- ENV SPARK_HOME=/opt/spark
- ENV PATH=$SPARK_HOME/bin:$PATH
- EXPOSE 4040 6066 7077 7078 8080 8081
Generamos una imagen (base-spark-hadoop:latest) del Dockerfile anterior Posteriormente arrancamos un cotenedor con puertos expuestos que necesita Spark Inspeccionar el contenedor Networks y Prot
Creamos la images base-spark-hadoop:latest :
- In: root@juan-Aspire-ES1-512:/my-dockerfile/base-spark-hadoop# docker build . -t base-spark-hadoop:latest
Listar las images :
- In: root@juan-Aspire-ES1-512:/# docker images
- Out: base-spark-hadoop latest f4e1f006f12e 14 hours ago 1.13GB
Arrancamos el contenedor efimero con puertos:
- In: juan-Aspire-ES1-512:/# docker run -it —rm \
-p 0.0.0.0:4040:4040 \
-p 0.0.0.0:6066:6066 \
-p 0.0.0.0:7077:7077 \
-p 0.0.0.0:7078:7078 \
-p 0.0.0.0:8080:8080 \
base-spark-hadoop
Listamos los contenedor en ejecución :
- In: root@juan-Aspire-ES1-512:/# docker ps
- Out: f6d5761cbbc6 base-spark-hadoop «/bin/sh -c /bin/bash» 4 minutes ago Up 4 minutes 0.0.0.0:4040->4040/tcp, 0.0.0.0:6066->6066/tcp, 0.0.0.0:7077-7078->7077-7078/tcp, 0.0.0.0:8080->8080/tcp, 8081/tcp inspiring_archimedes
Inspeccionar el contenedor :
- In: root@juan-Aspire-ES1-512:/# docker inspect f6d5761cbbc6
Out: «Networks»: {
«bridge»: {
«Gateway»: «172.17.0.1»,
«IPAddress»: «172.17.0.2«,
Comprobación de los Puertos expuestos :
- In: root@juan-Aspire-ES1-512:/# docker port f6d5761cbbc6
- Out: 7078/tcp -> 0.0.0.0:7078
- Out: 8080/tcp -> 0.0.0.0:8080
- Out: 4040/tcp -> 0.0.0.0:4040
- Out: 6066/tcp -> 0.0.0.0:6066
- Out: 7077/tcp -> 0.0.0.0:7077
Generamos el Master con la ip del host -h 172.17.0.2 Generamos un Worker URL spark://172.17.0.2:7077 -interface-Wed-Spar-Master Arrancamos interface-Wed-Spar-Master http://127.0.0.1:8080/
Arrancamos Master y un Worker :
- In: root@f6d5761cbbc6:/# cd opt
- In: root@f6d5761cbbc6:/opt# ./spark/sbin/start-master.sh -h 172.17.0.2
- Out: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark org.apache.spark.deploy.master.Master-1-f6d5761cbbc6.out
- In: root@f6d5761cbbc6:/opt# ./spark/sbin/start-worker.sh spark://172.17.0.2:7077
- Out: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark org.apache.spark.deploy.worker.Worker-1-f6d5761cbbc6.out
Arranca interface-Wed-Spar-Master http://127.0.0.1:8080/
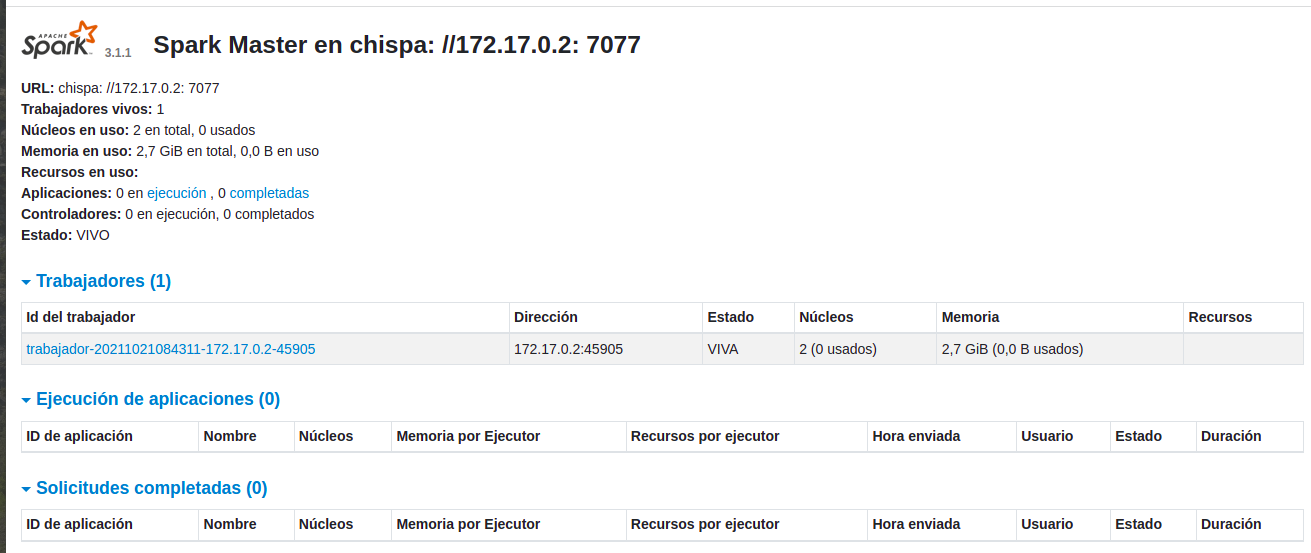
Paramos Worker y un Master :
- In: root@f6d5761cbbc6:/opt# ./spark/sbin/stop-worker.sh spark://172.17.0.2:7077
- Out: stopping org.apache.spark.deploy.worker.Worker
- In: root@f6d5761cbbc6:/opt# ./spark/sbin/stop-master.sh -h 172.17.0.2
- Out: stopping org.apache.spark.deploy.master.Master
Recapitulando:
Creamos con nano un Dockerfile para general (Que), realmente un contenedor que con Dockerfile hemos modificado con las especificaciones que deseamos, del cual se pude general una images nueva (docker buid) para conservar las capas agregadas a la images base . Posteriormente generamos el Master y Worker, (esto no es una puesta en producción) si no una ejecución de laboratorio para ver físicamente que es funcional.
Referencias: Entorno-Moreluz