

Nota: La necesidad de tener una computación en paralelo en sistema distribuido en my-portatil sin necesidad de uso de servidores físicos o virtuales para nuestros proyectos y laboratorios, usando en este caso PySpark, tenemos interesantes proyectos en GitHub usaremos uno de ellos en este post.
Spark-Standalone-Cluster-Docker
Nota: GitHub, es un servicio de alojamiento de Internet para el desarrollo de software y el control de versiones mediante Git . Proporciona el control de versiones distribuidas de Git más control de acceso , seguimiento de errores , solicitudes de funciones de software , gestión de tareas, se utiliza para proyectos de desarrollo de software de código abierto.
Nota: Necesitamos descargar las tres imágenes necesarias lo haremos con docker pull y verificaremos que se descargaron correctamente docker images .
Descargar las Imágenes necesarias:
- In: root@juan-SATELLITE-C55-C-1JM:/# docker pull andreper/jupyterlab
- In: root@juan-SATELLITE-C55-C-1JM:/# docker pull andreper/spark-master
- In: root@juan-SATELLITE-C55-C-1JM:/# docker pull andreper/spark-worker
Comprobación de las imágenes:
- In: root@juan-SATELLITE-C55-C-1JM:/# docker images
- Out: andreper/jupyterlab latest ef8c884fe26f 3 days ago 2.32GB
- Out: andreper/spark-worker latest 108b656cfcb4 3 days ago 1.48GB
- Out: andreper/spark-master latest 32ec47add810 3 days ago 1.48GB
Nota: Continuación creamos una carpeta para alojar el proyecto en la cual descargamos el fichero compose.yml, el cual lo ejecutaremos con docker-compose up tardara cierto tiempo, de pende de my-portatil una vez terminado podemos detener el cluster con Ctrl+c .
Creamos la carpeta donde alojamos el proyecto:
- In: root@juan-SATELLITE-C55-C-1JM:/# mkdir Apache-Spark-Standalone-Cluster-Docker
- In: root@juan-SATELLITE-C55-C-1JM:/# cd Apache-Spark-Standalone-Cluster-Docker
- In: root@juan-SATELLITE-C55-C-1JM:/Apache-Spark-Standalone-Cluster-Docker#
Descargamos compose.yml:
- In: root@juan-SATELLITE-C55-C-1JM:/Apache-Spark-Standalone-Cluster-Docker# curl -LO https://raw.githubusercontent.com/cluster-apps-on-docker/spark-standalone-cluster-on-docker/master/docker-compose.yml
- In: root@juan-SATELLITE-C55-C-1JM:/Apache-Spark-Standalone-Cluster-Docker# ls
- Out: docker-compose.yml
Ejecutar el fichero docker-compose.yml:
- In: root@juan-SATELLITE-C55-C-1JM:/Apache-Spark-Standalone-Cluster-Docker# docker-compose up
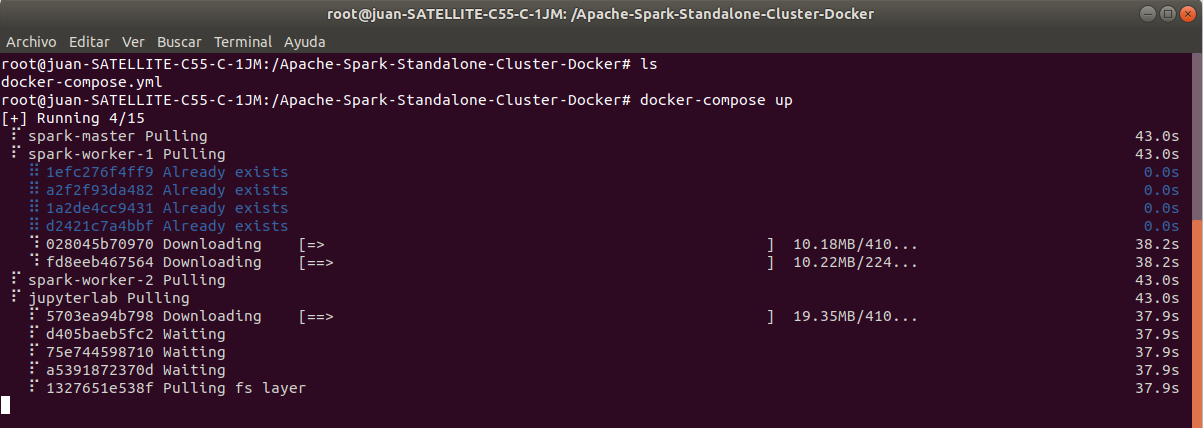
Nota: Escribir en el terminal Ctrl+c para detener el cluster.
Nota: Iniciamos de nuevo el cluster, tenemos una series de interfaz las cuales iniciaremos en el navegador
Iniciar las interfaz del Clúster
- Spark Master localhost:8080 Spark Master node
- Spark Worker 1 localhost:8081 Spark Worker node
- Spark Worker 2 localhost:8082 Spark Worker node
- Spark Driver localhost:4040 Interfaz-usuario-web de Spark Driver
- JupyterLab localhost:8888 Interfaz de la IDE-Jupyter
Arrancamos el cluster:
- In: root@juan-SATELLITE-C55-C-1JM:/Apache-Spark-Standalone-Cluster-Docker# docker-compose up
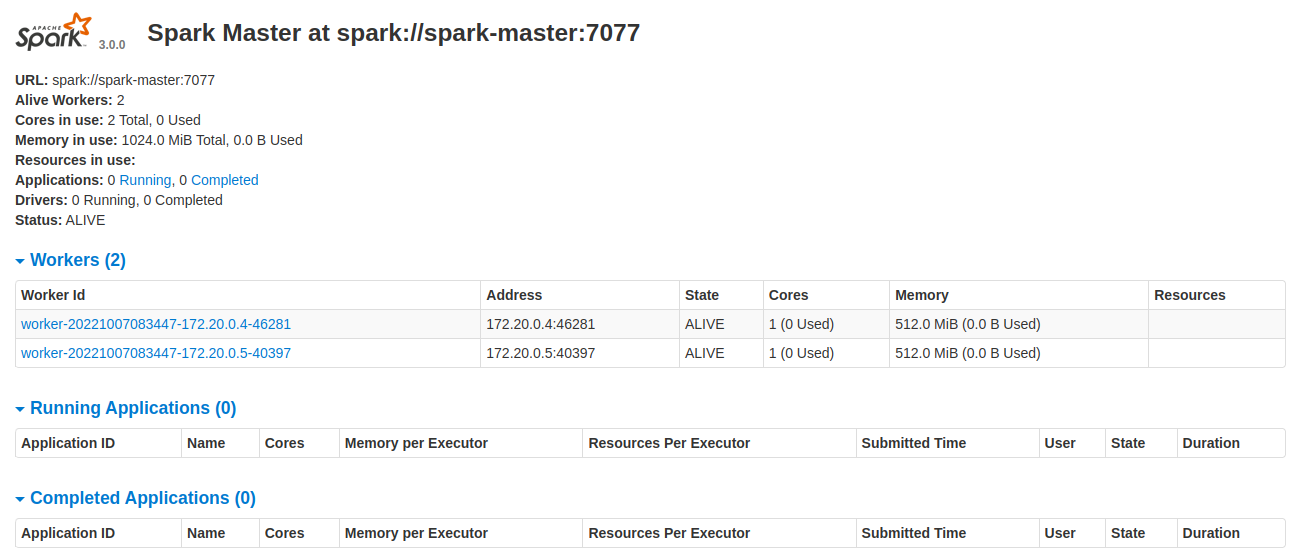
Nota: Iniciamos la Interfaz del Master pegando en nuestro navegador localhost:8080
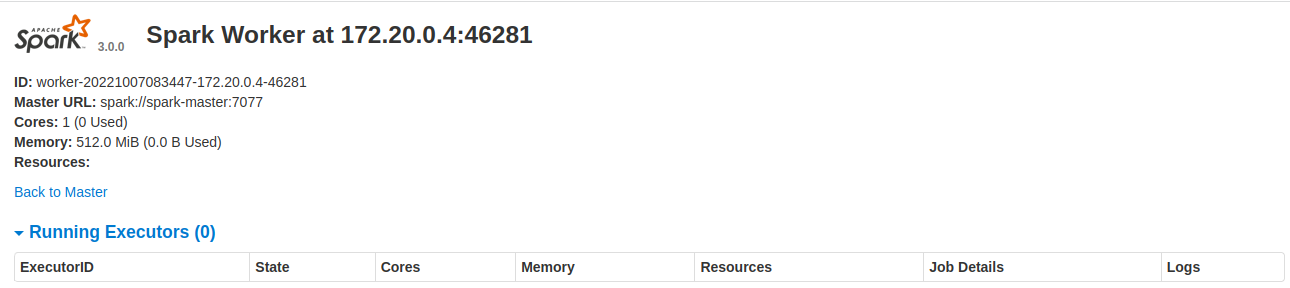
Nota: Iniciamos la Interfaz del Worker 1 pegando en nuestro navegador localhost:8081
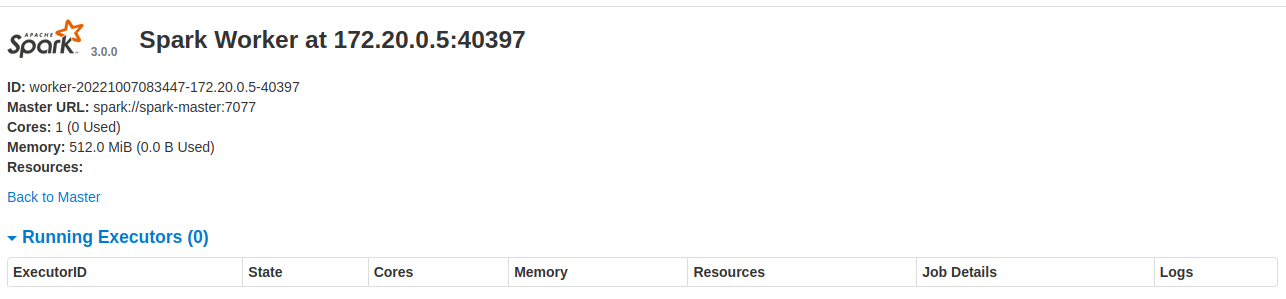
Nota: Iniciamos la Interfaz del Worker 2 pegando en nuestro navegador localhost:8082
Nota: Iniciamos la Interfaz de JupyterLab pegando en nuestro navegador localhost:8888.

Recapitulando:
Apache-Spark es framework de procesamiento distribuido paralelo en memoria más utilizado en el campo del análisis avanzado de Big Data. Al final tendremos un clúster de Apache-Spark completamente funcional generado con Docker y compuesto con un Nodo-Master , dos Nodos-Workerde y una interfaz de JupyterLab, en la cual tenemos nuestra API Apache Spark Python (PySpark) y un sistema de archivos distribuido Hadoop simulado (HDFS).
- Referencias: (Entorno–Moreluz)
- Referencias: github